пятница, 31 декабря 2010 г.
суббота, 25 декабря 2010 г.
пятница, 24 декабря 2010 г.
DirectGL progress
Ещё несколько демок прибыло:


Интересное затруднение возникло с mesh subsets, т. к. я не понимаю, каким точно образом attribute buffer управляет сабсетами меша. Чтобы добиться схожей функциональности, я выделил ограниченное кол-во индексных буферов для предполагаемых сабсетов (скажем, 8). Я просто обхожу attribute buffer и формирую индексные буферы сабсетов из главного индексного буфера. Новый индексный буфер выделяется только тогда, когда встречен соответствующий индекс в attribute буфере, поэтому расход памяти пока приемлемый. Можно и дальше развивать эту идею, но всё-таки интересно, как данный подход на самом деле реализован у Microsoft.





Интересное затруднение возникло с mesh subsets, т. к. я не понимаю, каким точно образом attribute buffer управляет сабсетами меша. Чтобы добиться схожей функциональности, я выделил ограниченное кол-во индексных буферов для предполагаемых сабсетов (скажем, 8). Я просто обхожу attribute buffer и формирую индексные буферы сабсетов из главного индексного буфера. Новый индексный буфер выделяется только тогда, когда встречен соответствующий индекс в attribute буфере, поэтому расход памяти пока приемлемый. Можно и дальше развивать эту идею, но всё-таки интересно, как данный подход на самом деле реализован у Microsoft.

С демкой multiple viewports я наткнулся на интересное различие между Direct3D 9 и OpenGL: в первом операция очистки ограничена границами вьюпорта, а в последнем - нет, т. е. чистится всё. Побороть различие удалось установкой scissor теста.


понедельник, 20 декабря 2010 г.
DirectGL progress
Порт ещё одной демки: occlusion query


Изначально я планировал портировать только ядро Direct3D 9, но желание перенести некоторые демки на OpenGL стало столь велико, что я засучил рукава и принялся писать реализацию интерфейса ID3DXMesh и обвязку для него, т. е. D3DXCreateBox(), D3DXCreateSphere() и т. д. Спортирую только самое необходимое, а Wine мне поможет. Кстати, в последнем отсутствует функция D3DXCreateTeapot(), поэтому я думаю просто сделать дамп меша Direct3D в текстовый файл и потом подключить его как .h.
Да, когда-то мы API просто изучали, а теперь мы их портируем :)
Да, когда-то мы API просто изучали, а теперь мы их портируем :)
четверг, 16 декабря 2010 г.
DirectGL progress
Спортировал ещё несколько демок, включая одну из DX SDK:










Все демки работают идентично Direct3D 9, за исключением той, что искривляет геометрию флага в вершинном шейдере: в D3D fixed-function pixel processing дружит с vertex shader, а в OpenGL - нет, по крайней мере в современных драйверах, поэтому изображение чёрное (я вывел в wireframe). Демка с жёлтым прямоугольником внутри синего - это мой собственный unit-test методов IDirect3DTexture9::LockRect и UnlockRect c RGBA8 форматом.
среда, 15 декабря 2010 г.
воскресенье, 12 декабря 2010 г.
Пальто
Забыл написать, что пальто из зелёного вельвета я всё-таки сшил.
Выглядит оно здорово, но меня не устроили пропорции: широковато в плечах, в талии не такое зауженное, как хотелось бы, да оказалось, что рукава должны быть по-длиннее, референс диктует правила :) Перешивать не хочу, т. к. его и так уже перекраивали по моей просьбе. Придётся поднакопить деньжат и попытаться ещё раз, с нуля. Думаю, во второй раз всё пойдёт проще, т. к. есть готовый образец и точно ясно, что нужно исправить.

Счастлив тот, кто сшил себе
В Гамбурге штанишки.
Благодарен он судьбе
За свои делишки.
четверг, 9 декабря 2010 г.
3DMark 11
Погонял бесплатную версию бенчмарка на iMac-е с HD 5750.
Тормозит (и сильно), при том что настройки в бесплатной версии - низкие, соответственно и качество... Чувствуется, что ребята создали задел "на будущее", т. к. на однопроцессорной ПЕЧи бенчмарк нормально работать не способен. На странице результатов http://3dmark.com/search можно увидеть, что нормальный fps достижим на системе из трёх ПЕЧей 480 и разогнанном Intel Core i7.
Просмотрел сейчас настройки Performance пакета и ошалел: паршивое разрешение 1280x720 без мультисемплинга и с трилинейной фильтрацией... И это еле ползает на топовых видеокартах! Пиздец.
Тормозит (и сильно), при том что настройки в бесплатной версии - низкие, соответственно и качество... Чувствуется, что ребята создали задел "на будущее", т. к. на однопроцессорной ПЕЧи бенчмарк нормально работать не способен. На странице результатов http://3dmark.com/search можно увидеть, что нормальный fps достижим на системе из трёх ПЕЧей 480 и разогнанном Intel Core i7.
Просмотрел сейчас настройки Performance пакета и ошалел: паршивое разрешение 1280x720 без мультисемплинга и с трилинейной фильтрацией... И это еле ползает на топовых видеокартах! Пиздец.
воскресенье, 5 декабря 2010 г.
DirectGL: linking and loading
Взял Direct3D 9 версию нашего проекта. Поменял файлы заголовков d3d на свои, подменил сдкейные lib-ы на зависимость от directgl, подпилил некоторые зависимости D3DX... И вся эта махина стартанула!!!
Начали трейситься вызовы, создался девайс Direct3D, swap chain, наперечислялись форматы и видеорежимы. Пошла загрузка уровня: создались вершинные декларации (кхм, как BLENDINDICES портировать?), 2D-текстуры, вершинные и индексные буферы, шейдеры (для них я пока сделал заглушку). В итоге упало на попытке чего-то отрисовать :)
Но большего пока и не надо! Как здорово обмануть проект и подсунуть ему фейковую обёртку, которая даже что-то делает. Теперь можно неспеша дебажиться и наращивать требуемый функционал :)
Update
Заставил загружаться в память игровой уровень. Это на самом деле просто, т. к. все ресурсы, которыми оперирует растеризатор, складываются из VB/IB, DXT-текстур, рендер таргетов и шейдеров (роль последних выполняет заглушка).
Интересно, что при заполнении текстуры через LockRect() во флагах обычно указывается 0, что означает, что мы можем как читать, так и писать по указателю. Чтобы только читать, можно указать флаг D3DLOCK_READONLY, но для заполнения нужно что-то вроде WRITEONLY. Можно было бы использовать usage D3DUSAGE_WRITEONLY при создании текстуры, но насколько я понял, этот флаг применяется только к (вершинному) буферу. В общем, для первого (и обычно единственного) lock-а приходится копировать данные из текстуры в PBO, а затем мапить буфер. Я рещил, что можно избежать этого шага, если хранить флажок bDirtyMip=true для текстуры, и на первом lock-e не копировать данные, а просто делать discard пиксельного буфера. После UnlockRect() флажок выставляется в false.
Если данные в текстуре всё равно невалидные и там мусор, то какая клиенту разница, чей это мусор: текстурный или буферный?
Начали трейситься вызовы, создался девайс Direct3D, swap chain, наперечислялись форматы и видеорежимы. Пошла загрузка уровня: создались вершинные декларации (кхм, как BLENDINDICES портировать?), 2D-текстуры, вершинные и индексные буферы, шейдеры (для них я пока сделал заглушку). В итоге упало на попытке чего-то отрисовать :)
Но большего пока и не надо! Как здорово обмануть проект и подсунуть ему фейковую обёртку, которая даже что-то делает. Теперь можно неспеша дебажиться и наращивать требуемый функционал :)
Update
Заставил загружаться в память игровой уровень. Это на самом деле просто, т. к. все ресурсы, которыми оперирует растеризатор, складываются из VB/IB, DXT-текстур, рендер таргетов и шейдеров (роль последних выполняет заглушка).
Интересно, что при заполнении текстуры через LockRect() во флагах обычно указывается 0, что означает, что мы можем как читать, так и писать по указателю. Чтобы только читать, можно указать флаг D3DLOCK_READONLY, но для заполнения нужно что-то вроде WRITEONLY. Можно было бы использовать usage D3DUSAGE_WRITEONLY при создании текстуры, но насколько я понял, этот флаг применяется только к (вершинному) буферу. В общем, для первого (и обычно единственного) lock-а приходится копировать данные из текстуры в PBO, а затем мапить буфер. Я рещил, что можно избежать этого шага, если хранить флажок bDirtyMip=true для текстуры, и на первом lock-e не копировать данные, а просто делать discard пиксельного буфера. После UnlockRect() флажок выставляется в false.
Если данные в текстуре всё равно невалидные и там мусор, то какая клиенту разница, чей это мусор: текстурный или буферный?
Нецензурщина
Каюсь, грешен.
Применил в коде goto, для удаления ресурсов при возникновении ошибки. Знаю, что это почти как мат, но без него придётся либо многократно дублировать код удаления, либо использовать исключения. Первое чревато, а второе не разрешено.
Применил в коде goto, для удаления ресурсов при возникновении ошибки. Знаю, что это почти как мат, но без него придётся либо многократно дублировать код удаления, либо использовать исключения. Первое чревато, а второе не разрешено.
среда, 24 ноября 2010 г.

понедельник, 22 ноября 2010 г.
DX9 game port
Вот и обещанный порт маленькой DX-игры:


Она использует минимум фич рендера, понадобилось реализовать только интерфейс ID3DXSprite. Его реализацию я нагло выдрал из Wine, сверяясь с описанием в DirectX SDK. Не реализован lockable back buffer, в который рисуются звёзды и выхлопы двигателя корабля, т. к. в OpenGL отсутствуют lockable buffers. Позже, думаю, для развлечения можно будет использовать pixel buffer object, но это полумеры, да и в крупных проектах не используется (разве что для редактора).
Также сделал наброски pure device, в виде наследника основного device. В pure device отсутствуют проверки на возможные ошибки в time-critical частях кода, чем сейчас изобилует основой device.
P. S. Wine штука интересная, время от времени я буду сверяться с ним в случае затруднений при портировании.
Update
Реализовал lockable back buffer. Для этого пришлось написать класс swap chain-а и усложнить логику создания render target - теперь он может быть текстурой, если lockable, и рендербуфером, если нет (а если задан мультисемплинг - только им). На ATI опять отгрёб проблемы, на этот раз с PBO - первый lock/unlock работает только первые три кадра, затем текстура не обновляется. Повторный даёт результат, поэтому я пока вставил затычку с пустым первым lock/unlock. На GeForce этой проблемы, как и ожидалось, нет.
Также заработал мультисемплинг и переход в fullscreen режим.
Update
Реализовал lockable back buffer. Для этого пришлось написать класс swap chain-а и усложнить логику создания render target - теперь он может быть текстурой, если lockable, и рендербуфером, если нет (а если задан мультисемплинг - только им). На ATI опять отгрёб проблемы, на этот раз с PBO - первый lock/unlock работает только первые три кадра, затем текстура не обновляется. Повторный даёт результат, поэтому я пока вставил затычку с пустым первым lock/unlock. На GeForce этой проблемы, как и ожидалось, нет.
Также заработал мультисемплинг и переход в fullscreen режим.
четверг, 18 ноября 2010 г.
DirectGL progress
Спортировал ещё несколько демок. С ростом codebase это становится всё проще и проще.



Следующий шаг - портирование на OpenGL небольшой DX9-игры с codesampler.com. Также я взял на вооружение исходники Wine, интересно посмотреть, как они реализовали некоторый функционал.
Затем в качестве пробы пера - компоновка с игровым проектом, над которым мы работаем сейчас. Попробуем хотя бы собраться, а дальше - попытка инициализация device, переход в fullscreen, создание ресурсов. Этого будет достаточно, чтобы признать задумку годной к использованию в следующем проекте.


Следующий шаг - портирование на OpenGL небольшой DX9-игры с codesampler.com. Также я взял на вооружение исходники Wine, интересно посмотреть, как они реализовали некоторый функционал.
Затем в качестве пробы пера - компоновка с игровым проектом, над которым мы работаем сейчас. Попробуем хотя бы собраться, а дальше - попытка инициализация device, переход в fullscreen, создание ресурсов. Этого будет достаточно, чтобы признать задумку годной к использованию в следующем проекте.
суббота, 13 ноября 2010 г.
DirectGL progress
Спортировал ещё одну демку, которая показывает принцип фильтрации MIP-уровней видеокартой:

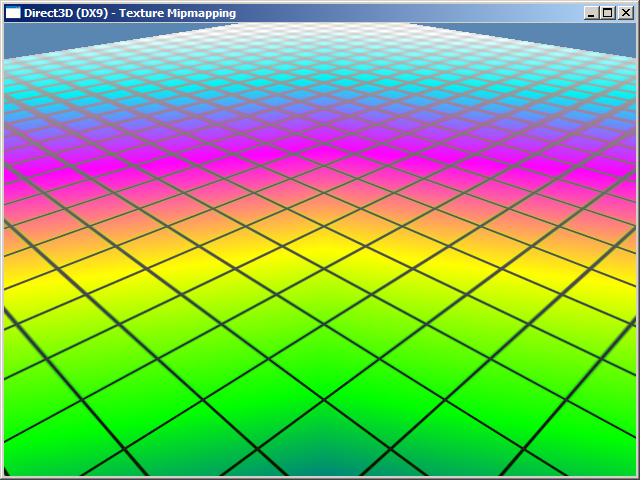
На codesampler.com есть OpenGL аналог этой D3D9-демки. Там mip-уровни загружаются через glTexImage2D(). Мне необходимо было спортировать функцию D3DXLoadSurfaceFromSurface(), которая, как я подозреваю, вызывает внутри ::StretchRect(). Этот API может нести на себе расширение GL_EXT_framebuffer_blit, которое я и использовал при портировании. Но что-то не заладилось у меня на ноутбуке: нулевые MIP-уровни source текстур не хотели блититься в подходящие MIP-уровни dest текстуры. Вернее, blit шёл всегда в нулевой MIP, как будто бы параметер level игнорируется. Я долго провозился с кодом, но так ничего толкового и не придумал.
Сегодня решил для пробы проверить на стационарном PC с GTX 260 - и всё заработало как надо. Это опять глючит GlukoGL, теперь на ATI :(.
Update
Нашёл причину бага на ATI: нужно включить mipmap фильтрацию для текстуры, если хотим блитить в mip-уровень больше 0. Маразм.
Update
Нашёл причину бага на ATI: нужно включить mipmap фильтрацию для текстуры, если хотим блитить в mip-уровень больше 0. Маразм.
среда, 10 ноября 2010 г.
Atonement
Вчера посмотрел этот фильм.
Удивительно, как я его пропустил и не посмотрел раньше. Это фильм о 13-летней девочке, которая из-за своей глупости и ревности не могла (или не хотела) отличить похоть от любви, а пошлость от страсти, и этим разрушила счастье двух молодых людей. Когда девочка стала 18-летней девушкой, она осознала, что натворила, но ничего исправить уже было нельзя. Она дожила до глубокой старости, неся эту боль внутри и не имея возможности избавиться от неё...
Удивительно, как я его пропустил и не посмотрел раньше. Это фильм о 13-летней девочке, которая из-за своей глупости и ревности не могла (или не хотела) отличить похоть от любви, а пошлость от страсти, и этим разрушила счастье двух молодых людей. Когда девочка стала 18-летней девушкой, она осознала, что натворила, но ничего исправить уже было нельзя. Она дожила до глубокой старости, неся эту боль внутри и не имея возможности избавиться от неё...
понедельник, 8 ноября 2010 г.
DirectGL progress
Заставил рисоваться несколько Direct3D 9 fixed-function демок через свой враппер: 5-й тутор из SDK и три демки с codesampler.com. Последние используются потому, что SDK бесстыжим образом использует во всю разные LPD3DXMESH и т. д., портирование которых не планируется. Только Core интерфейсы + небольшая часть D3DX (математика, загрузка текстур).




Исходный код демок никак не менялся, за исключением include-ов и lib.
воскресенье, 7 ноября 2010 г.
Рыба гниёт с головы
Я заметил, что утром, по пути на работу, я стал часто останавливаться в метро возле этого плаката:

Там ещё по-немецки Lebensqualitat beginnt im Kopf. Мне нравится стоять возле него и размышлять...

Там ещё по-немецки Lebensqualitat beginnt im Kopf. Мне нравится стоять возле него и размышлять...
суббота, 30 октября 2010 г.
DirectGL
Первый для меня проект по портированию Direct3D-тайтла на платформу MacOS X близится к концу, а тем временем моя голова уже полна мыслей, как оптимизировать этот процесс для будущих проектов.
Наш render team набил достаточно шишек, пытаясь запустить D3D-flow через трубопровод GlukoGL, но, как известно, на ошибках учатся! Вообще всё очень зависит от специфики проекта (скажем, гоночки с динамическим стримингом мира vs статическая загрузка, ARB-шейдеры vs GLSL), но тем не менее, можно выделить несколько задач, реализация которых облегчит портирование Direct3D игр на Маc:
1) Исходный код рендера неприкосновенен настолько, насколько это возможно. По сути, я подумываю написать статическую библиотеку, которая будет внешне мимикрировать Direct3D, а внутри транслировать все вызовы в команды GlukoGL. Нам необходимы по сути лишь несколько основых классов: Vertex/IndexBuffer, Query, VertexDeclaration и Device, чтобы получить картинку в wireframe, а дальше уже отлаживать шейдинг и остальные прибамбасы. По сути весь Device в нынешнем проекте писал и оптимизировал я, так что его Direct3D-like реализация уже имеется. Идея состоит в том, чтобы не просто сделать like-реализацию, а написать полную Direct3D-оболочку, внутри которой либо портировать функционал, либо делать stub-овые методы, в зависимости от условий проекта. Тогда код рендера практически не придётся трогать.
2) Жёсткий контроль за render states. Необходимо написать render state dumper, который будет опрашивать API на предмет всех мыслимых стэйтов и выводить их в файл/консоль. Тогда можно будет легко контролировать весь поток рендеринга, делая дампы стэйтов:
Cравнивая дампы в Direct3D и GlukoGL рендерах, можно легко отлавливать закравшиеся баги. Если какой-то стэйт потерян - останавливаемся и ищем ошибку. Полное соответствие всех стэйтов на всём протяжении отрисовки кадра здорово уменьшит нашу головную боль с отладкой.
3) Viewport Y-Axis Inversion.
Решать единообразно. Скажем, домножать .y компоненту вершины на -1 в вершинном шейдере после преобразования MVP матрицей. Тогда проблема инверсии оси Y нивелируется и при сэмплировании получившейся текстуры можно не возиться с текстурными координатами. Или, как вариант, подправить саму матрицу, чтобы не тратить команду шейдера.
Наш render team набил достаточно шишек, пытаясь запустить D3D-flow через трубопровод GlukoGL, но, как известно, на ошибках учатся! Вообще всё очень зависит от специфики проекта (скажем, гоночки с динамическим стримингом мира vs статическая загрузка, ARB-шейдеры vs GLSL), но тем не менее, можно выделить несколько задач, реализация которых облегчит портирование Direct3D игр на Маc:
1) Исходный код рендера неприкосновенен настолько, насколько это возможно. По сути, я подумываю написать статическую библиотеку, которая будет внешне мимикрировать Direct3D, а внутри транслировать все вызовы в команды GlukoGL. Нам необходимы по сути лишь несколько основых классов: Vertex/IndexBuffer, Query, VertexDeclaration и Device, чтобы получить картинку в wireframe, а дальше уже отлаживать шейдинг и остальные прибамбасы. По сути весь Device в нынешнем проекте писал и оптимизировал я, так что его Direct3D-like реализация уже имеется. Идея состоит в том, чтобы не просто сделать like-реализацию, а написать полную Direct3D-оболочку, внутри которой либо портировать функционал, либо делать stub-овые методы, в зависимости от условий проекта. Тогда код рендера практически не придётся трогать.
2) Жёсткий контроль за render states. Необходимо написать render state dumper, который будет опрашивать API на предмет всех мыслимых стэйтов и выводить их в файл/консоль. Тогда можно будет легко контролировать весь поток рендеринга, делая дампы стэйтов:
void SomePass::Render()
{
DumpRenderStates("begin.txt");
// a lot of render code here...
DumpRenderStates("end.txt");
}
Cравнивая дампы в Direct3D и GlukoGL рендерах, можно легко отлавливать закравшиеся баги. Если какой-то стэйт потерян - останавливаемся и ищем ошибку. Полное соответствие всех стэйтов на всём протяжении отрисовки кадра здорово уменьшит нашу головную боль с отладкой.
3) Viewport Y-Axis Inversion.
Решать единообразно. Скажем, домножать .y компоненту вершины на -1 в вершинном шейдере после преобразования MVP матрицей. Тогда проблема инверсии оси Y нивелируется и при сэмплировании получившейся текстуры можно не возиться с текстурными координатами. Или, как вариант, подправить саму матрицу, чтобы не тратить команду шейдера.
Clear: D3D vs GL
На днях наткнулся на интересную разницу в работе Direct3D 9 и OpenGL: в первом очистка depth буфера не зависит от того, разрешена маска записи в depth или нет, а вот в OpenGL - зависит. Это стало причиной бага в рендере, когда маска отключалась и после этого шла очистка буфера глубины. Скорее всего, с render target ситуация аналогичная.
четверг, 21 октября 2010 г.
Минеральный секретарь
Кстати, не многие как-то задумываются, что в новом 2011 году исполняется 20 лет со времени распада ЭСэСэСэР.
Но за истёкшие годы пациент работать так и не научился. Вместо этого он сдаёт кровь (нефть) и получает деньги. Патология какая-то, не лечится.
Но за истёкшие годы пациент работать так и не научился. Вместо этого он сдаёт кровь (нефть) и получает деньги. Патология какая-то, не лечится.

Он как-то сам собой развалился :-(
И ещё в догонку:

И ещё в догонку:

понедельник, 18 октября 2010 г.
Hello, DirectX 11!
Давно клянчил DX11-систему, но пока что такая была только за моей спиной. Я уже перекинул туда некоторые свои проекты, но вот теперь... Я заполучил новый iMac с видеокартой Radeon HD 5750!

Правда, на предыдущем компьютере был процессор Core i7 и 8 ГБ памяти, а на новом - только Core i5 и4 ГБ 8 ГБ, но ничего, более продвинутый GPU для меня важнее. Уже всё настроил, поставил Xcode и последние апдейты, осталось только поставить Windows 7 через Bootcamp и здравствуй, DirectX 11!
Update
Оказалось, что всё не так просто. Windows 7 я поставил (boot menu доступно при зажатии alt/option при старте), но вот драйверы для видеокарты не хотят распознавать железку. Я ставил каталист и для десктопной серии, и для мобильной, и драйверы из Apple Bootcamp - всё бестолку, определяется стандартный VGA адаптер да ещё пишется, что для него установлены самые подходящие драйверы. Погуглил: оказывается, некоторые тоже столкнулись с аналогичной проблемой - mid-2010 iMac-и имеют проблемы с видео драйвером из-под Windows (из-под Mac OS X понятно, что всё в порядке).
Update
Ура, драйверы установились! Нужны специальные, для late-2009 и mid-2010 iMac-ов, качать следует отсюда:

Правда, на предыдущем компьютере был процессор Core i7 и 8 ГБ памяти, а на новом - только Core i5 и
Update
Оказалось, что всё не так просто. Windows 7 я поставил (boot menu доступно при зажатии alt/option при старте), но вот драйверы для видеокарты не хотят распознавать железку. Я ставил каталист и для десктопной серии, и для мобильной, и драйверы из Apple Bootcamp - всё бестолку, определяется стандартный VGA адаптер да ещё пишется, что для него установлены самые подходящие драйверы. Погуглил: оказывается, некоторые тоже столкнулись с аналогичной проблемой - mid-2010 iMac-и имеют проблемы с видео драйвером из-под Windows (из-под Mac OS X понятно, что всё в порядке).
Update
Ура, драйверы установились! Нужны специальные, для late-2009 и mid-2010 iMac-ов, качать следует отсюда:

четверг, 14 октября 2010 г.
воскресенье, 10 октября 2010 г.
GPU, raytracing и транзисторы
С некоторых пор мне в глаза бросилась одна вещь: hi-end видеокарты NVIDIA и AMD стали похожи на маленькие "гробики". Да.
Если мысленно вернуться в конец 90-х и начало двухтысячных, то можно увидеть, что видеокарты внешне представляли собой простую зелёную или красную однослотовую плату, иногда увенчанную небольшим кулером системы охлаждения. В таком виде они не очень отличались, скажем, от звуковых плат или других плат расширения. Легкость тех решений объясняется просто: кол-во транзисторов в чипах исчислялось всего несколькими десятками миллионов, и в hi-end решениях требовалось минимальное активное охлаждение, а в low-end часто применялось пассивное. Размеры транзисторов измерялись десятыми долями микрон.
Первым тревожным звоночком стала GeForce FX, которая несла первый по-настоящему программируемый GPU. Но какой ценой? Больше ста миллионов транзисторов при техпроцессе в 0.13 микрон и система охлаждения, которая выла, как пылесос:

Эта видеокарта по габаритам, энергопотреблению, тепловыделению и производимому шуму значительно отличалась от GeForce 3/4. Позже NVIDIA удалось оптимизировать техпроцесс и low-end видеокарты NV4x даже выходили с пассивной системой охлаждения.
И всё же, чем дальше, тем более ясно прослеживается такая тенденция: кол-во транзисторов постоянно увеличивается, причём быстрее, чем мельчает техпроцесс, или другими словами, размеры этих самых транзисторов. Последняя GeForce ПЕЧ 480 - наглядный пример того, к какому энергопотреблению и тепловыделению можно прийти, если впихнуть в кристалл 512 скалярных процессоров, всякие КУДЫ и double-precision. Поэтому неудивительно, что даже middle-end решения вроде GTX 460 приходится одевать в СО в виде чёрного "гробика".
Понятно, что бесконечно этот увлекательный процесс усложнения чипов продолжаться не может. Сейчас техпроцесс имеет размер 40 нм, и планируется переход на 28 нм. Это позволит либо уменьшить размеры кристалла (и тепловыделение), либо увеличить кол-во транзисторов при неизменном размере. А скорее всего, учитывая постоянную гонку производительности, площади чипов и кол-во GPU-ядер вырастут ещё больше, несмотря на истончение техпроцесса. Я читал, что пределом для иммерсионного литографического процесса являются 15-16 нм, после которого наступит или застой, или будут разработаны новые методы производства транзисторов. В любом случае, количество GPU-ядер можно будет увеличить всего в несколько раз (ну, на порядок), а значит, увлекательная гонка производительности близка к финишу. Конечно, можно ещё оптимизировать архитектуру чипа, расположение транзисторов, наращивать память, сменить воздушную СО на водяную, утончить техпроцесс, поставить два GPU на одну плату, использовать SLI и т. д., но глядя на гробик 480 ПЕЧИ (да и Radeon HD тоже хорош), становится страшно от осознания простой вещи - видеокарты близко подошли к тому пределу, за которым их уже нельзя использовать в персональном компьютере пользователя. И становится ясно, что при существующих технологиях производства чипов увидеть рейтрейсинг в коробке PC - нереально. Нам нужна в 100 раз большая производительность, но достичь её при современных тенденциях к тепловыделению - невозможно.
Финита ля комедия :-|
Если мысленно вернуться в конец 90-х и начало двухтысячных, то можно увидеть, что видеокарты внешне представляли собой простую зелёную или красную однослотовую плату, иногда увенчанную небольшим кулером системы охлаждения. В таком виде они не очень отличались, скажем, от звуковых плат или других плат расширения. Легкость тех решений объясняется просто: кол-во транзисторов в чипах исчислялось всего несколькими десятками миллионов, и в hi-end решениях требовалось минимальное активное охлаждение, а в low-end часто применялось пассивное. Размеры транзисторов измерялись десятыми долями микрон.
Первым тревожным звоночком стала GeForce FX, которая несла первый по-настоящему программируемый GPU. Но какой ценой? Больше ста миллионов транзисторов при техпроцессе в 0.13 микрон и система охлаждения, которая выла, как пылесос:

Эта видеокарта по габаритам, энергопотреблению, тепловыделению и производимому шуму значительно отличалась от GeForce 3/4. Позже NVIDIA удалось оптимизировать техпроцесс и low-end видеокарты NV4x даже выходили с пассивной системой охлаждения.
И всё же, чем дальше, тем более ясно прослеживается такая тенденция: кол-во транзисторов постоянно увеличивается, причём быстрее, чем мельчает техпроцесс, или другими словами, размеры этих самых транзисторов. Последняя GeForce ПЕЧ 480 - наглядный пример того, к какому энергопотреблению и тепловыделению можно прийти, если впихнуть в кристалл 512 скалярных процессоров, всякие КУДЫ и double-precision. Поэтому неудивительно, что даже middle-end решения вроде GTX 460 приходится одевать в СО в виде чёрного "гробика".
Понятно, что бесконечно этот увлекательный процесс усложнения чипов продолжаться не может. Сейчас техпроцесс имеет размер 40 нм, и планируется переход на 28 нм. Это позволит либо уменьшить размеры кристалла (и тепловыделение), либо увеличить кол-во транзисторов при неизменном размере. А скорее всего, учитывая постоянную гонку производительности, площади чипов и кол-во GPU-ядер вырастут ещё больше, несмотря на истончение техпроцесса. Я читал, что пределом для иммерсионного литографического процесса являются 15-16 нм, после которого наступит или застой, или будут разработаны новые методы производства транзисторов. В любом случае, количество GPU-ядер можно будет увеличить всего в несколько раз (ну, на порядок), а значит, увлекательная гонка производительности близка к финишу. Конечно, можно ещё оптимизировать архитектуру чипа, расположение транзисторов, наращивать память, сменить воздушную СО на водяную, утончить техпроцесс, поставить два GPU на одну плату, использовать SLI и т. д., но глядя на гробик 480 ПЕЧИ (да и Radeon HD тоже хорош), становится страшно от осознания простой вещи - видеокарты близко подошли к тому пределу, за которым их уже нельзя использовать в персональном компьютере пользователя. И становится ясно, что при существующих технологиях производства чипов увидеть рейтрейсинг в коробке PC - нереально. Нам нужна в 100 раз большая производительность, но достичь её при современных тенденциях к тепловыделению - невозможно.
Финита ля комедия :-|
Apple Magic Mouse
После длительного юзания на работе дропнул дальнейшее использование этого девайса.
Гламурная мышь, но неудобная и непрактичная: тяжела из-за батареек, плохо скользит по коврику (а по голому столу - тем более), неудобно прижимать "виртуальную" правую клавишу и листать код в Xcode сенсором. Это всё равно как пытаться использовать сенсорную клавиатуру на экране вместо привычной физической - все подобные потуги обречены на провал, как и попытка заменить бумажную книгу её электронным суррогатом... Одним словом, когда я после длительного использования яблочного "тараканчика" подключил к маку стандартную двухкнопочную PC-мышь с колёсиком, то вздохнул с облегчением :)
Fail, Apple.
Гламурная мышь, но неудобная и непрактичная: тяжела из-за батареек, плохо скользит по коврику (а по голому столу - тем более), неудобно прижимать "виртуальную" правую клавишу и листать код в Xcode сенсором. Это всё равно как пытаться использовать сенсорную клавиатуру на экране вместо привычной физической - все подобные потуги обречены на провал, как и попытка заменить бумажную книгу её электронным суррогатом... Одним словом, когда я после длительного использования яблочного "тараканчика" подключил к маку стандартную двухкнопочную PC-мышь с колёсиком, то вздохнул с облегчением :)
Fail, Apple.
четверг, 7 октября 2010 г.
Fashion Week
Я получил от дизайнера одежды приглашение на Ukrainian Fashion Week:

Никогда не был на таких фэшинах.
Надо сходить интереса ради :)
Update
Сходил на это мероприятие. Всё было замечательно! Коллекция называлась "Весна-лето 2011", поэтому многие девушки были в прозрачных "туниках", через которые всё проглядывало. Понятно что внимания на то, что они там на себя надели, я уже не обращал.
суббота, 2 октября 2010 г.
Пальто
Шьёмся по-тихоньку :)



Это пока что только наброски из кусков материи, платье будет ушиваться на талии, подол станет короче. Белая выглядывающая полоска - это тыльная сторона подкладки.
А вот вблизи материал, из которого оно шьётся - итальянский зелёный вельвет:

По моей задумке, к платью будет прилагаться капюшон из чёрного бархата, который будет крепиться с тыльной стороны к подкладке пуговичками, он будет укрывать голову вместо шапки в холодное время и во время дождя. Сочетание зелёного и чёрного цветов кажется мне весьма эффектным, особенное если это вельвет и бархат :) Также в мою задачу входит сейчас поиск подходящих пуговиц, всего их необходимо 12 штук. Хочется достать пуговицы каплевидной формы, но не знаю, есть ли такие сейчас в продаже. Впрочем, это момент уже второстепенный.



Это пока что только наброски из кусков материи, платье будет ушиваться на талии, подол станет короче. Белая выглядывающая полоска - это тыльная сторона подкладки.
А вот вблизи материал, из которого оно шьётся - итальянский зелёный вельвет:

По моей задумке, к платью будет прилагаться капюшон из чёрного бархата, который будет крепиться с тыльной стороны к подкладке пуговичками, он будет укрывать голову вместо шапки в холодное время и во время дождя. Сочетание зелёного и чёрного цветов кажется мне весьма эффектным, особенное если это вельвет и бархат :) Также в мою задачу входит сейчас поиск подходящих пуговиц, всего их необходимо 12 штук. Хочется достать пуговицы каплевидной формы, но не знаю, есть ли такие сейчас в продаже. Впрочем, это момент уже второстепенный.
четверг, 30 сентября 2010 г.
N8
Прочитал про новый смартфон Nokia N8, и что его мол собрались продавать в городе бывшего мэра Лужкова Маскве, одновременно как и во всём мире. Хе-хе, Apple почему-то так не делает :)
Вообще, в роли догоняющей Nokia в конце-концов может и сможет создать что-нибудь этакое, только толку (как мне кажется) от этого будет немного. Проблема в том, что бренд Nokia перестал ассоциироваться с чем-то первоклассным, или, если выразиться более точно, он стал ассоциироваться с Унылым Говном, и люди с деньгами никогда не купят имиджевый смартфон этой марки. Гламурные кисо и богатые дяди купят Apple, кто-то купит что-то с WP7, кто-то - Nexus One. А Nokia...
-Что это у тебя за новый телефон?
-Nokia N8!
-A-a, понятно. (А про себя: вечно догоняющие лузеры, УГ).
P.S. Говорят, в 2011 у модных смартфонов будет новая фича: потеря сигнала при неправильном обхвате рукой :)
Вообще, в роли догоняющей Nokia в конце-концов может и сможет создать что-нибудь этакое, только толку (как мне кажется) от этого будет немного. Проблема в том, что бренд Nokia перестал ассоциироваться с чем-то первоклассным, или, если выразиться более точно, он стал ассоциироваться с Унылым Говном, и люди с деньгами никогда не купят имиджевый смартфон этой марки. Гламурные кисо и богатые дяди купят Apple, кто-то купит что-то с WP7, кто-то - Nexus One. А Nokia...
-Что это у тебя за новый телефон?
-Nokia N8!
-A-a, понятно. (А про себя: вечно догоняющие лузеры, УГ).
P.S. Говорят, в 2011 у модных смартфонов будет новая фича: потеря сигнала при неправильном обхвате рукой :)
вторник, 28 сентября 2010 г.
How a GPU Shader Cores Work
Весьма интересные слайды с SIGGRAPH 2010, описывающие в общих чертах, как работают современные GPU, чем они отличаются от x86 CPU, как работают ветвления и сокрытие латентности памяти внутри GPU:
From Shader Code to a Teraflop: How GPU Shader Cores Work
Приводятся основные архитектурные различия между современными Radeon HD 5870 и GeForce ПЕЧ 480. Также можно посмотреть более старую версию слайдов за 2008 год, где сравниваются ПЕЧ 280, HD 4870 и Larrabee.
Не пытайтесь прочитать всё за один присест, лучше растянуть на 2-3 дня :)
From Shader Code to a Teraflop: How GPU Shader Cores Work
Приводятся основные архитектурные различия между современными Radeon HD 5870 и GeForce ПЕЧ 480. Также можно посмотреть более старую версию слайдов за 2008 год, где сравниваются ПЕЧ 280, HD 4870 и Larrabee.
Не пытайтесь прочитать всё за один присест, лучше растянуть на 2-3 дня :)
воскресенье, 19 сентября 2010 г.
Occluder Fusion Problem
Есть у алгоритма penumbra wedges один существенный недостаток, бороться с которым очень сложно и в общем случае - невозможно. Недостаток заключается в том, что алгоритм неверно определяет coverage источника света в случае, если два или более ребра несколько раз перекрывают одну и ту же область - т. н. occluder fusion. Проблема вытекает из того, что пиксельный шейдер работает отдельно с каждым ребром, которое проецируется на источник света, а не со всеми сразу, и расчёт для каждого ребра никак не учитывают влияние "соседей". Как компромисс авторы в далёком 2003 предлагали использовать т. н. probabilistic approach, при котором силуэты от двух разных кастеров рисуются в отдельные RT и потом они смешиваются по формуле
Хотя single point silhouette approximation представляется мне более сложной и важной проблемой, серьёзно влияющей на визуальное качество теней, occluder fusion также не давал мне покоя и я потихоньку думал, как её можно обойти на DX 11 железе. Ясно, что проблема лежит в аналитическом методе расчёта пенумбры, из-за которого, собственно, мягкие тени и выглядят как настоящие тени, а не как их жалкое подобие. Правильное решение заключается в интегрировании площади источника света с помощью множества сэмплов на его поверхности, как делается, например, в методе depth complexity sampling. Но применённый алгоритм получается медленным и не годится для real-time.
Быстрое "решение" пришло в голову, когда я обдумывал преимущества использования coverage lookup table для упрощения пиксельного шейдера. Итак, у нас есть предрассчитанный coverage для ребра с произвольными координатами двух вершин. А что, если разбить источник света на N сэмплов, и вместо coverage предрассчитывать маску охвата, как это делают GPU при мультисэмплинге? Получается маска вида 0000101100100010, её можно сохранить в integer текстуре. В Direct3D 11 доступен формат DXGI_FORMAT_R32G32B32A32_UINT, так что можно разбить площадь и. с. на 128 сэмплов при последующей одной выборке в пиксельном шейдере.

Теперь, делая такую выборку для каждого отдельного ребра, мы может просто ORить маски охвата (SM 4.0 железо и выше умеет работать с отдельными битами) и в конце получить результирующую маску, которая и описывает правильный coverage. Теперь достаточно подсчитать количество битов, выставленных в 1 (в SM 5.0 для этого даже есть подходящий интринсик - countbits(uint4 value)) и получить отношение к общему их кол-ву. В результате мы корректно проинтегрируем скрытую (видимую) площадь источника света, представленную в промежутке [0..1], которую можно сразу записывать в coverage буфер.
И все :)
P. S. На работе в непосредственной близости от меня появилась DirectX 11 система (Windows 7 + Radeon HD 5850, так что дело скоро сдвинется с места).
что в результате даёт значение между двумя экстремумами. Также есть пейпр, где сабж пытались побороть с помощью penumbra wedges blending (Vincent Forest et al., Realistic Soft Shadows by Penumbra-Wedges Blending), но техника выглядит очень заумной и нежизнеспособной в real-time и не стоит подробного рассмотрения.c = max(Ca, Cb) + 1/2 * min(Ca, Cb)
Хотя single point silhouette approximation представляется мне более сложной и важной проблемой, серьёзно влияющей на визуальное качество теней, occluder fusion также не давал мне покоя и я потихоньку думал, как её можно обойти на DX 11 железе. Ясно, что проблема лежит в аналитическом методе расчёта пенумбры, из-за которого, собственно, мягкие тени и выглядят как настоящие тени, а не как их жалкое подобие. Правильное решение заключается в интегрировании площади источника света с помощью множества сэмплов на его поверхности, как делается, например, в методе depth complexity sampling. Но применённый алгоритм получается медленным и не годится для real-time.
Быстрое "решение" пришло в голову, когда я обдумывал преимущества использования coverage lookup table для упрощения пиксельного шейдера. Итак, у нас есть предрассчитанный coverage для ребра с произвольными координатами двух вершин. А что, если разбить источник света на N сэмплов, и вместо coverage предрассчитывать маску охвата, как это делают GPU при мультисэмплинге? Получается маска вида 0000101100100010, её можно сохранить в integer текстуре. В Direct3D 11 доступен формат DXGI_FORMAT_R32G32B32A32_UINT, так что можно разбить площадь и. с. на 128 сэмплов при последующей одной выборке в пиксельном шейдере.

Теперь, делая такую выборку для каждого отдельного ребра, мы может просто ORить маски охвата (SM 4.0 железо и выше умеет работать с отдельными битами) и в конце получить результирующую маску, которая и описывает правильный coverage. Теперь достаточно подсчитать количество битов, выставленных в 1 (в SM 5.0 для этого даже есть подходящий интринсик - countbits(uint4 value)) и получить отношение к общему их кол-ву. В результате мы корректно проинтегрируем скрытую (видимую) площадь источника света, представленную в промежутке [0..1], которую можно сразу записывать в coverage буфер.
И все :)
P. S. На работе в непосредственной близости от меня появилась DirectX 11 система (Windows 7 + Radeon HD 5850, так что дело скоро сдвинется с места).
четверг, 16 сентября 2010 г.
Враг у ворот
Солдаты!
Все вы - граждане и защитники нашей необъятной Родины-матери! Напоминаю вам об этом ещё раз, перед тем как наши доблестные войска пересекут линию фронта! Стоять, блять, насмерть, позади - Дефолт-сити, она же - Маськва!
Все вы - граждане и защитники нашей необъятной Родины-матери! Напоминаю вам об этом ещё раз, перед тем как наши доблестные войска пересекут линию фронта! Стоять, блять, насмерть, позади - Дефолт-сити, она же - Маськва!
среда, 15 сентября 2010 г.
Bootice
Ну, граждане пограммисты, OpenGL-тролли, задроты, и просто закоренелые девственники - соскучились по записям?
В выходные слетела у меня Windows 7 (на ноуте). Бог его знает, что там произошло, только загружаться с определённого момента она стала ну о-очень долго и зависала с пустым экраном и одиноким ездящим курсором. MSI предусмотрели восстановление изначальной Vista с hidden partition на HDD, только эта утилита отформатировала мне диск C: и стабильно падала в ребут на этапе инициализации. Т. к. привода DVD в ноуте нет, пришлось научиться устанавливать Windows 7 с флешки.
Как оказалось, если просто распаковать iso-образ дистрибутива Windows на флешку, выставить в BIOS загрузку с неё, и ребутнуть систему то получим либо сообщение "Bootmgr is missing", либо "Disk error", в зависимости от флешки. Решить проблему удалось с помощью сайта flashboot.ru, где я скачал необходимые утилиты для правильного форматирования флешки и размещения на ней дистрибутива OS. Всё заработало с первой попытки и я успешно поставил Windows 7 Ultimate (была Professional). Пиратка с торрента, конечно, но я же уже заплатил за Vista при покупке ноута! MS, думаю, хватит и этого, к тому же это для безобидного домашнего пользования :)
Жаль только, что Ultimate грузится как-то медленнее, чем Professional, а ещё раз всё переустанавливать не хочется.
О житии :)
Надоело носить всякую дрянь с рынка шмоток, поэтому решил на осень сшить себе пальто. Шью себе впервые в жизни, так что опыт этот для меня новый, интересный :) Нашёл в Киеве ателье, договорился с дизайнером, показал фотки - что и как должно выглядеть... Уже нашли для меня подходящий зелёный вельвет, из Италии. Похоже, влетит мне эта штучка в 800$ (в основном - за работу), ну да фиг с ними, деньгами, молодость ведь бывает только раз в жизни. Образец для подражания - зелёный сюртук 19 века, так сказать nec plus ultra для молодого человека того времени, подпиленный для повседневного ношения на улице в наши дни.
Быть может, вы ещё его увидите :)
В выходные слетела у меня Windows 7 (на ноуте). Бог его знает, что там произошло, только загружаться с определённого момента она стала ну о-очень долго и зависала с пустым экраном и одиноким ездящим курсором. MSI предусмотрели восстановление изначальной Vista с hidden partition на HDD, только эта утилита отформатировала мне диск C: и стабильно падала в ребут на этапе инициализации. Т. к. привода DVD в ноуте нет, пришлось научиться устанавливать Windows 7 с флешки.
Как оказалось, если просто распаковать iso-образ дистрибутива Windows на флешку, выставить в BIOS загрузку с неё, и ребутнуть систему то получим либо сообщение "Bootmgr is missing", либо "Disk error", в зависимости от флешки. Решить проблему удалось с помощью сайта flashboot.ru, где я скачал необходимые утилиты для правильного форматирования флешки и размещения на ней дистрибутива OS. Всё заработало с первой попытки и я успешно поставил Windows 7 Ultimate (была Professional). Пиратка с торрента, конечно, но я же уже заплатил за Vista при покупке ноута! MS, думаю, хватит и этого, к тому же это для безобидного домашнего пользования :)
Жаль только, что Ultimate грузится как-то медленнее, чем Professional, а ещё раз всё переустанавливать не хочется.
О житии :)
Надоело носить всякую дрянь с рынка шмоток, поэтому решил на осень сшить себе пальто. Шью себе впервые в жизни, так что опыт этот для меня новый, интересный :) Нашёл в Киеве ателье, договорился с дизайнером, показал фотки - что и как должно выглядеть... Уже нашли для меня подходящий зелёный вельвет, из Италии. Похоже, влетит мне эта штучка в 800$ (в основном - за работу), ну да фиг с ними, деньгами, молодость ведь бывает только раз в жизни. Образец для подражания - зелёный сюртук 19 века, так сказать nec plus ultra для молодого человека того времени, подпиленный для повседневного ношения на улице в наши дни.
Быть может, вы ещё его увидите :)
вторник, 7 сентября 2010 г.
VBO state reduction
Я всё же придерживаюсь мнения, что правильный способ разгона рендера - это уменьшение state changes. Я реализовал наиболее оптимальную загрузку всех костей в bindable buffers (всё-таки DX 10 фича на Mac!), на очереди встала оптимизация VBO.
Т. к. каждая часть модели (голова, туловище, руки и т. д.) в портируемом проекте находится в отдельном буфере вершин/индексов (в терминологии движка - vertex/index stream), то приходится делать множество вызовов glBindBuffer() плюс делать setup вершинных атрибутов через glVertexAttribArrayPointer(), и я вам скажу, что количества вызовов получаются страшными |(o_0)| Поэтому вполне закономерно меня посетила такая идея: рассортировать всю геометрию по типам формата вершины и загнать все кусочки VB/IB в один большой буфер вершин. Тогда достаточно лишь один раз установить VB/IB и задать смещения для атрибутов, а дальше уже рисовать нужную геометрию - экономия state changes немалая.
К сожалению, в GlukoGL 2.0 отсутствует возможность указать base vertex location непосредственно в DIP-e, а только через смещение во всё той же злополучной glVertexAttribArrayPointer(). Если мы объединяем все VB в один, то очевидно что индексы во всех индексных буферах (кроме первого) становятся невалидными. Поэтому при сливании индексов в общий IB к ним добавлялся текущий base vertex location общего VB. Кроме того, индексы в "обрезках" IB хранились в формате USHORT (что очевидно), для общего IB они преобразовывались в UINT, т. к. адресация запросто вылезает за 2^16 вершин. Также skinned модели содержали свои LOD-ы в "обрезках", поэтому дополнительно пришлось повозиться с оффсетами по памяти и другой подобной белибердой.
Не буду описывать все проблемы, которые возникли у меня с GlukoGL на NVIDIA, пока я реализовывал "склейку". Скажу только, что схема заработала и геометрия успешно рисуется через новый codepath. State changes, такие как glBindBuffer / glVertexAttribArrayPointer / glEnableVertexAttribArray уменьшились существенно - в несколько раз.
Что до производительности - в случае небольшого кол-ва видимой геометрии есть видимый прирост fps, в случае тяжёлых сцен прирост держится "на честном слове" и частенько уходит в 0. Мы всё ещё упираемся во всякие гадкие вызовы GlukoGL, которые просаживают произодительность. Ну и как оптимизировать кучу DIP-ов при текущем data set-е - тоже неясно :(
Т. к. каждая часть модели (голова, туловище, руки и т. д.) в портируемом проекте находится в отдельном буфере вершин/индексов (в терминологии движка - vertex/index stream), то приходится делать множество вызовов glBindBuffer() плюс делать setup вершинных атрибутов через glVertexAttribArrayPointer(), и я вам скажу, что количества вызовов получаются страшными |(o_0)| Поэтому вполне закономерно меня посетила такая идея: рассортировать всю геометрию по типам формата вершины и загнать все кусочки VB/IB в один большой буфер вершин. Тогда достаточно лишь один раз установить VB/IB и задать смещения для атрибутов, а дальше уже рисовать нужную геометрию - экономия state changes немалая.
К сожалению, в GlukoGL 2.0 отсутствует возможность указать base vertex location непосредственно в DIP-e, а только через смещение во всё той же злополучной glVertexAttribArrayPointer(). Если мы объединяем все VB в один, то очевидно что индексы во всех индексных буферах (кроме первого) становятся невалидными. Поэтому при сливании индексов в общий IB к ним добавлялся текущий base vertex location общего VB. Кроме того, индексы в "обрезках" IB хранились в формате USHORT (что очевидно), для общего IB они преобразовывались в UINT, т. к. адресация запросто вылезает за 2^16 вершин. Также skinned модели содержали свои LOD-ы в "обрезках", поэтому дополнительно пришлось повозиться с оффсетами по памяти и другой подобной белибердой.
Не буду описывать все проблемы, которые возникли у меня с GlukoGL на NVIDIA, пока я реализовывал "склейку". Скажу только, что схема заработала и геометрия успешно рисуется через новый codepath. State changes, такие как glBindBuffer / glVertexAttribArrayPointer / glEnableVertexAttribArray уменьшились существенно - в несколько раз.
Что до производительности - в случае небольшого кол-ва видимой геометрии есть видимый прирост fps, в случае тяжёлых сцен прирост держится "на честном слове" и частенько уходит в 0. Мы всё ещё упираемся во всякие гадкие вызовы GlukoGL, которые просаживают произодительность. Ну и как оптимизировать кучу DIP-ов при текущем data set-е - тоже неясно :(
понедельник, 6 сентября 2010 г.
Жесть оцинкованная
В последнее время я подсел на чтиво в авторстве gansspb. Чем больше читаю, тем больше хочется. Жгёт товарищ :)
Кстати, мы с ним одногодки.
Кстати, мы с ним одногодки.
пятница, 3 сентября 2010 г.
My work iMac 27
Теперь и у меня на рабочем столе появился iMac (до этого стоял MacPro + монитор Philips 23 дюйма). У новой машины процессор Core i7 (да здравствует быстрая компиляция!), но, к сожалению, видеокарта ATI предыдущего поколения - HD 4850, а я уж хотел было доставить Windows 7 через bootcamp и засесть на выходных за DirectX 11 :( Ну ничего, когда-нибудь в контору придут новые iMac-и c AMD HD 6000 и я договорюсь об обмене :)
На фотках - процесс "раздевания" и запуска этой гламурной машинки:



Глянцевый Samsung XL2370 кажется карликом перед S-IPS матрицей айМака :)
М-да... В той дыре, где я жил и трудился раньше, работать за таким компьютером было можно только в мечтах, ибо денех на эту вещицу не было ни у меня, ни у моих соседей, ни у знакомых моих соседей...
Поэтому и пишу здесь о этом. Спасибо, тебе, Джонатан, за дизайн!
P.S. А макось+Хcode всё равно кака :)
четверг, 2 сентября 2010 г.
четверг, 26 августа 2010 г.
Slow GLSL linking
Я только диву даюсь, какие сюрпризы можно отгребрать, юзая ГлюкоGL.
В портируемом рендерере кости для персонажей заливаются небольшими порциями: по 15-50 костей на секцию (лицо, руки, ноги и т. д.) Вот пришла в голову такая оптимизация: кости для всех видимых в кадре skinned персонажей заливать за один "присест" в bindable buffer, а в шейдере использовать offset для выборки. Т. к. костей (матрицы 3x4) много (> 5000), то по идее мы нехило разгружаем драйвер, делая такой батчинг. В D3D9 так поступить не смогли, ну а тут сам бог велел: у нас GLSL + SM 4.0 min. sys. req.
Т. к. float4 получается много (5000 * 3 = 15000 и более), а максимальный размер bindable buffer - 4K float4, то пришлось использовать 5 буферов, и хранить дополнительно индекс буфера, из которого шейдер должен сделать выборку. И вот тут то у меня и ждал "приятный сюрприз": время компоновки шейдеров при использовании магических строчек вида
фюреру Стиви, в Apple следят за качеством OpenGL драйверов.
Ну хоть батчинг не придётся сливать в унитаз, а вот отладка в Windows превратилась в кошмар - > 10 мин на загрузку уровня.
В портируемом рендерере кости для персонажей заливаются небольшими порциями: по 15-50 костей на секцию (лицо, руки, ноги и т. д.) Вот пришла в голову такая оптимизация: кости для всех видимых в кадре skinned персонажей заливать за один "присест" в bindable buffer, а в шейдере использовать offset для выборки. Т. к. костей (матрицы 3x4) много (> 5000), то по идее мы нехило разгружаем драйвер, делая такой батчинг. В D3D9 так поступить не смогли, ну а тут сам бог велел: у нас GLSL + SM 4.0 min. sys. req.
Т. к. float4 получается много (5000 * 3 = 15000 и более), а максимальный размер bindable buffer - 4K float4, то пришлось использовать 5 буферов, и хранить дополнительно индекс буфера, из которого шейдер должен сделать выборку. И вот тут то у меня и ждал "приятный сюрприз": время компоновки шейдеров при использовании магических строчек вида
bindable uniform vec4 bones[4096];начало дико увеличиваться: для ~100 пар vs/ps с 10 с. до 10 минут! Да-да. Меняю размеры буферов и их количество до одного - время уменьшается. OMFG, что же ты там, зараза, можешь такое делать?! Какой индус решил повы*быв***ся своими знаниями в оптимизации кода при компоновке этих шейдеров? Эту компоновку, как известно, все нормальные разработчики видели в гробу, в белых тапочках... Короче кидаюсь на Mac, начинаю лихорадочно проверять работу кода на GF и ATI - всё нормально, ~100 пар линкуется за 5 с! Слава
Ну хоть батчинг не придётся сливать в унитаз, а вот отладка в Windows превратилась в кошмар - > 10 мин на загрузку уровня.
"Ревизор" Гоголя
Воистину, каждый человек ближе к 30 должен перечитать/пересмотреть ещё раз это произведение. Потому что оно - гениально.
воскресенье, 22 августа 2010 г.
OpenCL
Случайно наткнулся на инфу о том, что ATI ввели interoperability между OpenCL и Direct3D 10. Не то чтобы меня сильно интересовали OpenCL/CUDA, но ATI отказывается делать поддержку DirectCompute 4.1 для low-level и мобильных 4-х тысячников (кроме HD 47xx и 48xx). А хочется, например, силуэты считать на GPU, а не на калеке x86.
Для взаимодействия с D3D 10 Khronos ввели расширение cl_khr_d3d10_sharing (кстати у NVidia уже доступно взаимодействие с D3D 11). ATI Stream SDK 2.2 его уже поддерживает, для моей карточки - в режиме беты. Я запускал сэмплы - работают, производительность так себе, ну да всё равно "на поиграться" хватит.
Поэтому решил потихоньку освоиться в OpenCL и заюзать его, где получится, вместо DirectCompute. Сегодня наваял тестовую программу, которая инициализирует этот самый "ОпенКЛ", загружает kernel для суммирования элементов двух массивов, запускает на выполнение и считывает результат в сис. память. Работает.
Плохо только, что нет поддержки D3D 11 (хотя, по сути, дело времени), и что надо ставить дополнительно драйверы OpenCL, чтобы заменить DirectCompute.
Для взаимодействия с D3D 10 Khronos ввели расширение cl_khr_d3d10_sharing (кстати у NVidia уже доступно взаимодействие с D3D 11). ATI Stream SDK 2.2 его уже поддерживает, для моей карточки - в режиме беты. Я запускал сэмплы - работают, производительность так себе, ну да всё равно "на поиграться" хватит.
Поэтому решил потихоньку освоиться в OpenCL и заюзать его, где получится, вместо DirectCompute. Сегодня наваял тестовую программу, которая инициализирует этот самый "ОпенКЛ", загружает kernel для суммирования элементов двух массивов, запускает на выполнение и считывает результат в сис. память. Работает.
Плохо только, что нет поддержки D3D 11 (хотя, по сути, дело времени), и что надо ставить дополнительно драйверы OpenCL, чтобы заменить DirectCompute.
суббота, 21 августа 2010 г.
Gattaca
Think about this:
AntonVincent... Vincent...
Where's the shore? We’re too far out...
Vincent
You wanna quit?
Anton
We’re too far out!!!
Vincent
You wanna quit?!?!
Anton
No!
...
Anton
Vincent!.. How are you doing this, Vincent?
How have you done any of this?
We have to go back.
Vincent
It's too late for that, we're closer to the other side!
(Anton looks towards the empty horizon)
Anton
What other side?
You wanna drown us both?!
Vincent
You wanna know how I did it?
This is how I did it, Anton:
I never saved anything for the swim back!
понедельник, 16 августа 2010 г.

воскресенье, 8 августа 2010 г.
среда, 4 августа 2010 г.
Slow OpenGL vertex pipe
На работе в проекте столкнулись со следующей проблемой: OpenGL медленно работает при большом количестве DIP-ов.
Дипов много: на тестовом уровне - около 4000. На каждый вызов приходится смена вершинного и индексного буферов, установка шейдерных юниформов, текстур и иногда кое-каких стейтов. Direct3D версия каким-то образом умудряется всё это расхлёбывать - видно что CPU bound, но performance в пределах допустимого. Наш же OpenGL порт в текущем виде догнать Direct3D версию, похоже, не в состоянии. С вопросами "почему так много" - не ко мне, мы всего лишь делаем порт существующего Direct3D рендера, который работает (у)довлетворительно.
Разобрал енджин так, чтобы рисовались только анимированые персонажи в wireframe - получилось в районе 400 дипов при 30-40 персонажах. Direct3D рендер переваривает это за 14-15 ms, OpenGL - вдвое медленнее. Применение различных constraints на кол-во установок стейтов показали, что тормозит связка glVertexAttribPointer()/glDrawElements(). Снизить кол-во VAP-ов (3000)невозможно, т. к. нет другого способа указывать драйверу, откуда брать вершинные данные. Существует расширение GL_ARB_vertex_array_object, но пока на моей конфигурации (WinXP + GeForceПЕЧ 260) оно не даёт ощутимого прироста.
Хуже всего, что в сети почти нет никакой информации, как можно соптимизировать такую ситуацию хотя бы под одного вендора (NVIDIA). Гугл выдаёт ссылки на треды и пейпры, в которых настоятельно рекомендуется "подключить VBO". Что делать, если уже использован оптимальный codepath, неясно.
Думаю отложить на время все свои изыски "в прекрасном и высоком" и заняться написанием демки, в которой будет рисоваться множество однотипной геометрии (сферы или ещё что-то), и посмотреть, как ведёт себя драйвер и сколько fps можно из него выжать при 1k дипов и разных форматах вершины.
Мне просто стало интересно.
Update:

Update:
156 fps при 1000 дипов (Core 2 Quad + GTX 260). Не всё так плохо.
Выяснилась интересная подробность работы железа: если шейдер не использует какие-то вершинные атрибуты из буфера вершин, то они не читаются из видеопамяти. Т. е. скажем, формат вершины может быть хоть 100 байт, но если вершинный шейдер использует только позицию, то выбираться из памяти будут только соответствующие данные, а не вся вершина. При задействовании же всех атрибутов из 40 кб вершины в указанном выше тесте скорость падает до 50 fps.
Update:
Перенёс программу на Mac (это было просто, т. к. я использовал glut). При выборке в вершинном шейдере всех атрибутов на GeForce наблюдается падение скорости, аналогично как это происходит в Windows. На iMac с HD 4850 падения скорости - нет, fps держится в пределах 120 кадров, т. е. приблизительно аналогично GTX 260 в лёгком режиме. И ещё одно - на Mac+ATI gl_Position не мэпится на нулевой generic attribute, как и положено по стандарту.
Дипов много: на тестовом уровне - около 4000. На каждый вызов приходится смена вершинного и индексного буферов, установка шейдерных юниформов, текстур и иногда кое-каких стейтов. Direct3D версия каким-то образом умудряется всё это расхлёбывать - видно что CPU bound, но performance в пределах допустимого. Наш же OpenGL порт в текущем виде догнать Direct3D версию, похоже, не в состоянии. С вопросами "почему так много" - не ко мне, мы всего лишь делаем порт существующего Direct3D рендера, который работает (у)довлетворительно.
Разобрал енджин так, чтобы рисовались только анимированые персонажи в wireframe - получилось в районе 400 дипов при 30-40 персонажах. Direct3D рендер переваривает это за 14-15 ms, OpenGL - вдвое медленнее. Применение различных constraints на кол-во установок стейтов показали, что тормозит связка glVertexAttribPointer()/glDrawElements(). Снизить кол-во VAP-ов (3000)
Хуже всего, что в сети почти нет никакой информации, как можно соптимизировать такую ситуацию хотя бы под одного вендора (NVIDIA). Гугл выдаёт ссылки на треды и пейпры, в которых настоятельно рекомендуется "подключить VBO". Что делать, если уже использован оптимальный codepath, неясно.
Думаю отложить на время все свои изыски "в прекрасном и высоком" и заняться написанием демки, в которой будет рисоваться множество однотипной геометрии (сферы или ещё что-то), и посмотреть, как ведёт себя драйвер и сколько fps можно из него выжать при 1k дипов и разных форматах вершины.
Мне просто стало интересно.
Update:

Сидел на выходных, писал тест-апп. Рисуется моделька Макрона (финальный босс в Quake 2) 1000 раз, по дипу на модельку (я привёл только меш крупным планом, в демке они все крутятся на своих позициях в виде решётки). В меше (дипе) - 1200 треугольников. В вершине - позиция и нормаль, также делал выравнивание вершины до 32 байт.
Удалось уложиться в 38 ms (~26 fps) на моём ноуте с HD 4330 и проце Celeron M. IMHO очень неплохо - 1 200 000 треугольников на мобильной конфигурации. Завтра побегу тестировать на рабочей лошадке.
Update:
156 fps при 1000 дипов (Core 2 Quad + GTX 260). Не всё так плохо.
Выяснилась интересная подробность работы железа: если шейдер не использует какие-то вершинные атрибуты из буфера вершин, то они не читаются из видеопамяти. Т. е. скажем, формат вершины может быть хоть 100 байт, но если вершинный шейдер использует только позицию, то выбираться из памяти будут только соответствующие данные, а не вся вершина. При задействовании же всех атрибутов из 40 кб вершины в указанном выше тесте скорость падает до 50 fps.
Update:
Перенёс программу на Mac (это было просто, т. к. я использовал glut). При выборке в вершинном шейдере всех атрибутов на GeForce наблюдается падение скорости, аналогично как это происходит в Windows. На iMac с HD 4850 падения скорости - нет, fps держится в пределах 120 кадров, т. е. приблизительно аналогично GTX 260 в лёгком режиме. И ещё одно - на Mac+ATI gl_Position не мэпится на нулевой generic attribute, как и положено по стандарту.
понедельник, 2 августа 2010 г.
Silhouette compute shader
Написал тестовую реализацию на CPU и окончательно определился, как считать силуэты в вычислительном шейдере.
Вообще, силуэты можно искать двумя способами:
1) Идём по всем треугольникам, для каждого определяем, различается ли знак скалярного произведения (между нормалью и позицией) каждого смежного треугольника, и если да, то добавляем общее для этих треугольников ребро в силуэт.
2) Идём по всем рёбрам, для каждого определяем знак скалярного произведения смежных треугольников, если они различаются, добавляем ребро в силуэт.
Для первого способа адаптирован геометрический шейдер. Он несколько менее эффективный чем второй, т. к. на каждый треугольник приходится делать по четыре dot-a, хотя теоретически достаточно одного. Учитывая, что shading rate у GS низкий, это приемлемо.
Второй способ идеально подходит для вычислительного шейдера. Расчёт силуэтов проводим в два этапа: на первом определяем ориентацию всех треугольников относительно всех сэмплов, на втором - проверяем ориентацию смежных треугольников, добавляем ребро.
Первый шаг можно описать псевдокодом как-то так: step 1
Т. е. CS получает на вход буфер нормалей треугольников, делает для каждого сэмпла dot() и считает маску. Маска записывается в write-only буфер.
Для второго шага определяем структуры следующего вида:
На входе CS - буфер вершин меша и буфер структур edge, на выходе - буфер структур sil_edge. Каждый тред занят своим ребром, псевдокод второго шага: step 2. Силуэтные рёбра получаются уникальными, но каждое хранит маску сэмплов, для которых ребро определено как силуэтное. На этапе вытягивания волюма ещё один CS (или GS, но тогда придётся дублировать маску для каждой вершины, что suxx) может из одного ребра вытянуть несколько квадов, ориентируясь по маске.
Вот такой вот простой алгоритм, но на VS/GS его не реализовать, спасает только GPGPU.
Вообще, силуэты можно искать двумя способами:
1) Идём по всем треугольникам, для каждого определяем, различается ли знак скалярного произведения (между нормалью и позицией) каждого смежного треугольника, и если да, то добавляем общее для этих треугольников ребро в силуэт.
2) Идём по всем рёбрам, для каждого определяем знак скалярного произведения смежных треугольников, если они различаются, добавляем ребро в силуэт.
Для первого способа адаптирован геометрический шейдер. Он несколько менее эффективный чем второй, т. к. на каждый треугольник приходится делать по четыре dot-a, хотя теоретически достаточно одного. Учитывая, что shading rate у GS низкий, это приемлемо.
Второй способ идеально подходит для вычислительного шейдера. Расчёт силуэтов проводим в два этапа: на первом определяем ориентацию всех треугольников относительно всех сэмплов, на втором - проверяем ориентацию смежных треугольников, добавляем ребро.
Первый шаг можно описать псевдокодом как-то так: step 1
Т. е. CS получает на вход буфер нормалей треугольников, делает для каждого сэмпла dot() и считает маску. Маска записывается в write-only буфер.
Для второго шага определяем структуры следующего вида:
struct edgeГде а, b - индексы в буфере вершин (во второй структуре - сами вершины), left, right - индексы смежных треугольников, mask - маска сэмплов, для которых ребро определяется как силуэтное.
{
uint a;
uint b;
uint left;
uint right;
};
struct sil_edge
{
vec3 a
vec3 b;
uint mask;
}
На входе CS - буфер вершин меша и буфер структур edge, на выходе - буфер структур sil_edge. Каждый тред занят своим ребром, псевдокод второго шага: step 2. Силуэтные рёбра получаются уникальными, но каждое хранит маску сэмплов, для которых ребро определено как силуэтное. На этапе вытягивания волюма ещё один CS (или GS, но тогда придётся дублировать маску для каждой вершины, что suxx) может из одного ребра вытянуть несколько квадов, ориентируясь по маске.
Вот такой вот простой алгоритм, но на VS/GS его не реализовать, спасает только GPGPU.
воскресенье, 1 августа 2010 г.
пятница, 30 июля 2010 г.
четверг, 29 июля 2010 г.
Single point silhouette approximation
По-новой реализовал поиск силуэтов и построение теневого объёма на GPU. На этот раз я решил воспользоваться изюминкой Direct3D 11 и превратил структуру источника света в класс с собственными методами, т. к. гонять структуру по функциям aka C-style скучно.
Даже this поддерживается, хотя в SDK я не нашёл упоминания об этом keyword.

Раз уж я снова решил заняться мягкими тенями, то нужно рассказать об одной проблеме, которую необходимо преодолеть для достижения реалистичности пенумбры. Дело в том, что теневые объёмы (и карты теней тоже), строятся по упрощённой схеме - как они видны из центра источника света. Всё ок, пока нам нужны только примитивные, жёсткие тени или же мягкие тени, полученные каким-нить размазыванием жёстких (а что? пипл хавает). Но если источник света протяжённый, то shadow caster должен рассматриваться с позиций, по крайней мере, нескольких сэмплов на поверхности этого источника. В случае карт теней придётся рендерить кастер в отдельные карты N раз, в случае теневых объёмов - искать силуэт и вытягивать объём в геометрическом шейдере N раз. Это слишком сильно бьёт по производительности, и поэтому даже в случае мягких теней всё равно используют single point approximation.
К сожалению, такое отступление от честного подхода даром не проходит - пенумбра в некоторых случаях выглядит неестественно, как бы overshadowed, что портит впечатление. Особенно это заметно в случае penumbra wedges: авторы алгоритма как-то приводили картинки с искажённой пенумброй и эталоном, точно такие же отклонения были и у меня.

Кроме того, из-за аппроксимации силуэтные рёбра могут меняться неожиданным образом, перескакивая с ребра не ребро, если геометрия объекта грубая (коробка, например), что ведёт к penumbrae jumping.
В случае penumbra wedges выхода два: либо искать и рисовать теневые объёмы по N раз (а также рассчитывать N раз пенумбру в шейдере), либо искать силуэт каким-то особым образом, так, чтобы учесть все сэмплы на поверхности и. с. Учитывая, что теневые объёмы и так крайне прожорливы к филлрейту, первый вариант малореалистичен (хотя и очень прост в реализации). Интересен второй вариант, при котором учитываются все сэмплы, но дубликаты силуэтных рёбер при этом отбрасываются. Таким образом исходный теневой объём и пенумбра лишь немного "прибавят в весе". Неясно, насколько этот подход правилен, результаты сможет показать только тестовый рендер.
Хуже всего, что стандартными средствами Direct3D 11 невозможно отбрасывать рёбра-дубликаты, т. к. геометрический шейдер не имеет доступа к топологии всего меша. Кроме того, если на вход GS можно подавать индексированную геометрию, то на выходе получаем только неиндексированную. Т. е. shared by index вершины размножаются и мы никак не можем сохранить какое-то общее для них свойство (добавлены в силуэт или нет, например). Я продумал разные варианты поиска и отбрасывания дубликатов, и все они говорят одно - придётся подключать тормоз CPU. Но выходом может стать использование DirectCompute. Подключаем к CS буфер вершин и буфер индексов, находим силуэтные рёбра и кладём их в append buffer. Вполне так неплохо может получиться: одно ребро - один тред, натравить целый мультипроцессор на меш, вот он нам всё быстро и посчитает.
Update
Реализовал на CPU расчёт от нескольких сэмплов и понял свою ошибку. Мы можем постараться и сделать силуэтное ребро уникальным (без дубликатов), но из него всё равно нужно вытягивать N квадов (где N - кол-во сэмплов, для которых ребро является силуэтным), при этом квады будут иметь разные направления! Другими словами, придётся рисовать теневой объём N раз.
Вот тесты для одного и четырёх сэмплов:


На этом простом примере, даже в wireframe ясно, насколько сильно разнится результат в случае протяжённого источника света, если мухлевать и считать честно. Неудивительно, что вроде бы "честный" метод penumbra wedges даёт нереалистичную пенумбру.
Надо считать честно, и это достаточно печально, т. к. по скорости не сулит ничего хорошего. Можно было бы попробовать рисовать один теневой объём (из центра и. с.), а вот пенумбру считать для всех уникальных силуэтных ребёр, но, к сожалению, расчёт пенумбры привязан к жёсткому теневому объёму. Дело в том, что само значение в пенумбре можно только отнять или прибавить к исходному, и вот именно исходное значение и даётся жёстким теневым объёмом. В пиксельном шейдере его вычислить нет возможности, т. к. оно определяется топологией сцены.
Пожалуй, я всё же опционально реализую множество теневых объёмов, хотя бы для визуального сравнения, но для сложных сцен это не годится. Ещё попробую рассчитывать полноценную пенумбру при одном теневом объёме - возможно, визуально это даст улучшения, хотя метод потеряет корректность.
понедельник, 26 июля 2010 г.
Баг в геометрическом шейдере
Вот уже почти два часа ночи, и я нашёл, в чём причина бага.
Разница в том, что если использовать .fx формат D3DX, то с глобальными константами всё ок. Если же использовать простые шейдеры, то глобальные константы, например вида
считаются находящимися в дефолтном cbuffer, который создаёт компилятор. Поэтому, чтобы вы там ни прописали в шейдере, компилятор это выбросит, а GPU будет ожидать данные из буфера.
Зараза, хоть бы warning выдавал!
Разница в том, что если использовать .fx формат D3DX, то с глобальными константами всё ок. Если же использовать простые шейдеры, то глобальные константы, например вида
const float4 g_plane = float4(1., 0., 0., 1.);
считаются находящимися в дефолтном cbuffer, который создаёт компилятор. Поэтому, чтобы вы там ни прописали в шейдере, компилятор это выбросит, а GPU будет ожидать данные из буфера.
Зараза, хоть бы warning выдавал!
воскресенье, 25 июля 2010 г.
О слугах народа
«Утром мажу бутерброд –
Сразу мысль: а как народ?
И икра не лезет в горло,
И компот не льется в рот...»
iPhone
Я так понимаю, что если Яблочники имеют наглось продавать свой ойФон по бешенным ценам, а миллионы его всё-таки покупают, то крызис уже закончился?
суббота, 24 июля 2010 г.
Inception
Посмотрел этот опус. Я разочарован. Ну почему, почему решительно все режиссёры после отличных картин (Нолан после "Тёмного рыцаря", Снайдер после "300") начинают снимать всякую охинею? Все эти небылицы со снами, которые понапридумывал тов. Нолан (претензия на "Матрицу"?), вызывают откровенную скуку и мысли о зря потраченных кровных. Постоянные стрелялки во снах с какими-то охранниками в костюмах заставляют искать в кинозале Кнопку Быстрой Перемотки, т. к. всё это "не по-настоящему", а значит полная туфта. Всё, заканчиваю рецензию, фильм не заслуживает более длинной. Ну вы короче всё поняли :)
P.S. Я, кажется, догадываюсь, кто сыграет камео Джокера в следующем "Бэтмене"!
P.S. Я, кажется, догадываюсь, кто сыграет камео Джокера в следующем "Бэтмене"!
пятница, 23 июля 2010 г.
Оптимизация
Сегодня по работе оптимизировал одну функцию в движке, длиной строк в 20. Всякие if-ы, array compaction, вызов glUniform*()... Беда в том, что эта функция вызывается много тысяч раз (> 50k), и это создаёт нагрузку на CPU и драйвер.
Надо было оптимизировать. Пораскинув мозгами, я вдруг понял, что можно применить принцип "лучше день потерять, зато потом за пять минут долететь". Осознав, что конкретно для этой функции можно сделать precompute данных, что можно реплицировать входные константы в несколько массивов и таким образом избежать "неизбежного" array compaction, что можно не делать switch по типу, а хранить адрес нужной функции, то переписав код функции и сделав рефакторинг уложился в одну строчку - тот самый вызов glUniform*() по адресу с предрассчитанными аргументами.
Ещё одним "открытием" стало то, что program object кэширует свои юниформы, так что данные в них выживают после смены программ. Благодаря этому оказалось возможным сделать проверку на предмет изменения данных и не телипать лишний раз API/драйвер если данные не изменились. Замер показал, что кол-во необходимых вызовов снижается до 5-6k, что при 400 DIP-ах является вполне приемлемым.
Надо было оптимизировать. Пораскинув мозгами, я вдруг понял, что можно применить принцип "лучше день потерять, зато потом за пять минут долететь". Осознав, что конкретно для этой функции можно сделать precompute данных, что можно реплицировать входные константы в несколько массивов и таким образом избежать "неизбежного" array compaction, что можно не делать switch по типу, а хранить адрес нужной функции, то переписав код функции и сделав рефакторинг уложился в одну строчку - тот самый вызов glUniform*() по адресу с предрассчитанными аргументами.
Ещё одним "открытием" стало то, что program object кэширует свои юниформы, так что данные в них выживают после смены программ. Благодаря этому оказалось возможным сделать проверку на предмет изменения данных и не телипать лишний раз API/драйвер если данные не изменились. Замер показал, что кол-во необходимых вызовов снижается до 5-6k, что при 400 DIP-ах является вполне приемлемым.
воскресенье, 18 июля 2010 г.
Глянец
Зарплата теперь позволяет мне приобретать такие штучки, на которые раньше я только пускал слюни. Вот и приобрёл для своего рабочего места монитор Samsung XL2370 с "ЭЛ-И-ДИ" подсветкой матрицы, т. к. пялиться в дешёвенькую девятнашку от Dell-a уже нет мочи: старый, маленький, VGA-DVI переходник мылит шрифты, ублюдский макосёвый интерфейс на этом мониторе еле помещается...
Я конечно, понимаю Ubisoft, да и любая другая компания в такой ситуации сэкономит - типа видно что-то, да и ладно! А т. к. крайним в такой ситуации остался именно я (начальству пох - у него бюджет), и пялиться в это "чудо" мне по 8 часов в день пять дней в неделю (четверть жизненного времени), то не долго размышляя, полазил по розетке и выбрал приглянувшийся девайс. Ну какой, какой смысл давить жабу, если крайним остался я сам? Всё равно он будет мой (хоть и на работе), смогу в любое время забрать, если что. Монитор, конечно, вышел дороговатым (барыги накрутили почти до 400$), зато покупаются такие девайсы с прицелом на 3-4 года эксплуатации (да и на глазах, как известно, не экономят). К тому же я хочу приходить на работу с радостью, зная, что там меня ждёт не дождётся кравивая и милая глазам вещь. Да, я таков! :)
Всё, довольно на сегодня.
P. S. Завтра ещё может быть выложу фотки монитора "вживую" и опишу его достоинства и недостатки.
Update
Кое-как нашёл время сфоткать обновку. На экране - заставка по мотивам Матрицы.



Я конечно, понимаю Ubisoft, да и любая другая компания в такой ситуации сэкономит - типа видно что-то, да и ладно! А т. к. крайним в такой ситуации остался именно я (начальству пох - у него бюджет), и пялиться в это "чудо" мне по 8 часов в день пять дней в неделю (четверть жизненного времени), то не долго размышляя, полазил по розетке и выбрал приглянувшийся девайс. Ну какой, какой смысл давить жабу, если крайним остался я сам? Всё равно он будет мой (хоть и на работе), смогу в любое время забрать, если что. Монитор, конечно, вышел дороговатым (барыги накрутили почти до 400$), зато покупаются такие девайсы с прицелом на 3-4 года эксплуатации (да и на глазах, как известно, не экономят). К тому же я хочу приходить на работу с радостью, зная, что там меня ждёт не дождётся кравивая и милая глазам вещь. Да, я таков! :)
Всё, довольно на сегодня.
P. S. Завтра ещё может быть выложу фотки монитора "вживую" и опишу его достоинства и недостатки.
Update
Кое-как нашёл время сфоткать обновку. На экране - заставка по мотивам Матрицы.



четверг, 15 июля 2010 г.
понедельник, 5 июля 2010 г.
No Doubt - Running
Нашёл у No Doubt прекрасную композицию - Running. Очень мило, и можно увидеть редкие кадры - историю No Doubt "в картинках".
Конец истории
Ну вот наконец и я добрался до IMAX-a и посмотрел Toy Story 3.
Что тут сказать - пожалуй, один из самых удачных мультфильмов Pixar, (наравне с великолепными Ratatouille и WALLE), завершивший трилогию Историй Игрушек.
Срежессирован и нарисован мастерски. Не думаю, что большинству зрителей интересны такие тонкости, но замечу, что игрушки Энди в 2010 выглядят точно так же, как и в 1995, что не может не радовать. Зато все усовершенствования RenderMan-а, внедрённые за эти годы, создатели применили в рендеринге окружения - объёмный свет, яркое солнце, сочная зелёная трава, DoF (не очень, кстати, уместный в стерео), и т. п. Больше деталей в людях, больше анимации в действиях, одним словом - мир Toy Story 3 ближе к настоящему, чем таковым был пластиковый мир первой серии, но вот сами игрушки, по задумке кудесников из Pixar, остались неподвластны времени.
Сюжет получился, на мой взгляд, удачным - без провалов и нелепиц, действия плавно перетекают одно в другое, постепенно подводя зрителя к финалу трилогии. Честно говоря, у меня в конце глаза становились влажными, т. к. я понимал, что Pixar показывают - здесь они навсегда прощаются со своими (может быть, самыми любимыми), творениями. Иногда хотелось крикнуть им: "Стойте, нет! Что же вы делаете, так нельзя!!!" Для тех, кто уже посмотрел мультфильм, в комментарии написан спойлер, для остальных же скажу, что всё закончилось в итоге благополучно (а как же иначе, мультик ведь детский).
Для граждан незалежной Украины: украинское озвучивание получилось на редкость хорошим и слух не резало - я даже не замечал, на каком языке ведутся диалоги. Одним словом, к озвучиванию подошли добросовестно. А ставший традиционным короткометражный мультфильм (на этот раз - Day & Night) озвучил... Арсений Яценюк, что лично мне было очень приятно. Уж не знаю, чья это была идея, и кто кому заплатил, но PR вашел удачным :)
Ну вот и всё, конец Истории Игрушек. Вердикт: успех. Если кто-то в детстве увлекался этим мультиком - идти однозначно.
P.S. Пару слов об IMAX. Ходил на этот формат впервые (Blockbuster в Киеве), стерео хорошее, без "призраков", хотя я ожидал немного большего. Сперва есть ощущение плоскости некоторых сцен, но через полчаса сознание приспосабливается и начинает охотнее верить в трёхмерность картинки. Экран как бы "нависает" над сидящими ниже зрителями, иногда кажется, что до него можно дотронуться рукой. Яркость из-за очков падает прилично.
Что тут сказать - пожалуй, один из самых удачных мультфильмов Pixar, (наравне с великолепными Ratatouille и WALLE), завершивший трилогию Историй Игрушек.
Срежессирован и нарисован мастерски. Не думаю, что большинству зрителей интересны такие тонкости, но замечу, что игрушки Энди в 2010 выглядят точно так же, как и в 1995, что не может не радовать. Зато все усовершенствования RenderMan-а, внедрённые за эти годы, создатели применили в рендеринге окружения - объёмный свет, яркое солнце, сочная зелёная трава, DoF (не очень, кстати, уместный в стерео), и т. п. Больше деталей в людях, больше анимации в действиях, одним словом - мир Toy Story 3 ближе к настоящему, чем таковым был пластиковый мир первой серии, но вот сами игрушки, по задумке кудесников из Pixar, остались неподвластны времени.
Сюжет получился, на мой взгляд, удачным - без провалов и нелепиц, действия плавно перетекают одно в другое, постепенно подводя зрителя к финалу трилогии. Честно говоря, у меня в конце глаза становились влажными, т. к. я понимал, что Pixar показывают - здесь они навсегда прощаются со своими (может быть, самыми любимыми), творениями. Иногда хотелось крикнуть им: "Стойте, нет! Что же вы делаете, так нельзя!!!" Для тех, кто уже посмотрел мультфильм, в комментарии написан спойлер, для остальных же скажу, что всё закончилось в итоге благополучно (а как же иначе, мультик ведь детский).
Для граждан незалежной Украины: украинское озвучивание получилось на редкость хорошим и слух не резало - я даже не замечал, на каком языке ведутся диалоги. Одним словом, к озвучиванию подошли добросовестно. А ставший традиционным короткометражный мультфильм (на этот раз - Day & Night) озвучил... Арсений Яценюк, что лично мне было очень приятно. Уж не знаю, чья это была идея, и кто кому заплатил, но PR вашел удачным :)
Ну вот и всё, конец Истории Игрушек. Вердикт: успех. Если кто-то в детстве увлекался этим мультиком - идти однозначно.
P.S. Пару слов об IMAX. Ходил на этот формат впервые (Blockbuster в Киеве), стерео хорошее, без "призраков", хотя я ожидал немного большего. Сперва есть ощущение плоскости некоторых сцен, но через полчаса сознание приспосабливается и начинает охотнее верить в трёхмерность картинки. Экран как бы "нависает" над сидящими ниже зрителями, иногда кажется, что до него можно дотронуться рукой. Яркость из-за очков падает прилично.
среда, 30 июня 2010 г.
GS on 4330
Вчера наваял тестовую реализацию поиска силуэтов в geometry shader (реализация-то у меня и раньше была, но все коды остались далеко дома, пришлось всё делать заново).
Цифры такие:
Primitive_______Faces_____FPS
Sphere__________960______1220
Sphere__________3868_____1013
ChamferBox______4784_____962
Sphere__________16128____548
Т. е. даже для высокополигональных моделей (ну не 100 тысяч полигонов, конечно) low-end HW показывает хорошую скорость. К слову, шейдинг той же сферы вызывает намного более сильное падение числа кадров, нежели увеличение нагрузки на GS.
Думается, hi-end HW сможет без труда обрабатывать в GS до полумиллиона треугольников.
Цифры такие:
Primitive_______Faces_____FPS
Sphere__________960______1220
Sphere__________3868_____1013
ChamferBox______4784_____962
Sphere__________16128____548
Т. е. даже для высокополигональных моделей (ну не 100 тысяч полигонов, конечно) low-end HW показывает хорошую скорость. К слову, шейдинг той же сферы вызывает намного более сильное падение числа кадров, нежели увеличение нагрузки на GS.
Думается, hi-end HW сможет без труда обрабатывать в GS до полумиллиона треугольников.
суббота, 26 июня 2010 г.
Penumbra Construction
Взял свои старые (2008 г) разработки в конструировании пенумбры в GS, переписал и соптимизировал код.
Видео, как это работает для прямоугольного источника света:
Кстати, я как-то возился со своей демкой WALLE (надо выложить архив с ней), и выяснилось, что боттлнеком в ней был вовсе не pixel shader, а geometry shader. Было это на видеокарте Radeon HD 2400, в которой эта стадия тормозила безбожно, так же как и на первых G8x от NVidia. Но из тестов на своей HD 5770 я сделал вывод, что geometry shader стал работать ощутимо быстрее, чем раньше, и теперь его можно относительно безболезненно использовать даже в случае сложной геометрии.
Видео, как это работает для прямоугольного источника света:
Кстати, я как-то возился со своей демкой WALLE (надо выложить архив с ней), и выяснилось, что боттлнеком в ней был вовсе не pixel shader, а geometry shader. Было это на видеокарте Radeon HD 2400, в которой эта стадия тормозила безбожно, так же как и на первых G8x от NVidia. Но из тестов на своей HD 5770 я сделал вывод, что geometry shader стал работать ощутимо быстрее, чем раньше, и теперь его можно относительно безболезненно использовать даже в случае сложной геометрии.
четверг, 24 июня 2010 г.

понедельник, 21 июня 2010 г.
Just New Lookups
Продолжаю копать тему таблиц для теней.
Выяснилось, что авторы используют coverage с диапазоном значений [0..0.5] (заглянул в пейпр), тогда как я в позапрошлом посте показал таблицы с диапазоном [-0.5..0.5] (ноль в этом диапазоне представляется серым цветом). Отличие состоит в том, что оригинальные penumbra wedges рисуются двумя полуклиньями, и для каждого делается либо аддитивный, либо субтрактивный блендинг (деление на два полуклина было необходимо из-за нестыковки между пенумброй и границой чёткой тени, разделение на две части решало проблему). Deferred shaded подход к закраске требует рассчитывать положительное или отрицательное значение coverage (-0.5..0.5), ориентируясь по знаку z компоненты векторного произведения в шейдере.
С этим расчётом таблицы и строились. Но уже в процессе подготовки я понял, что с выборкой в шейдере предрассчитанного значения я тоже сталкиваюсь с проблемой нестыковки на границе чётких теней, из-за ограниченного разрешения субтекстур. Для обхода проблемы я планировал разбить шейдинг пенумбры на два этапа: основную часть закрашивать шейдером с lookup таблицы, а остальные пиксели, близкие к чётким границам - без таблицы. Теперь же мне в голову пришла такая мысль: подготовить таблицу с диапазоном значений [0..0.5], а знак продолжать вычислять в шейдере (две-три инструкции). Т. е. вот есть у нас пиксель на границе чёткой тени. Coverage тут может быть либо 0.5, либо -0.5, как фишка ляжет. Сэмплируем значения, близкие к 0.5 из таблицы, а знак определяем вычислением. Это уберёт большинство проблем, а остальные можно залечить в screen-space.
Пока как-то так. Конечно, окончательные выводы можно будет сделать только после тестов.
Вот как выглядят новые таблицы:


Выглядят они более "правильно", из-за симметрии что-ли. Размер субтекстуры - 32х32, т. е. получается таблица размерностью 1024x1024, при формате R8_UNORM займёт 1 MB видеопамяти (таблицу таких размеров использовали авторы оригинального алгоритма). Возможно, для минимизации проблем с точностью придётся использовать субтекстуру 64x64, а это уже 16 MB видеопамяти.
Выяснилось, что авторы используют coverage с диапазоном значений [0..0.5] (заглянул в пейпр), тогда как я в позапрошлом посте показал таблицы с диапазоном [-0.5..0.5] (ноль в этом диапазоне представляется серым цветом). Отличие состоит в том, что оригинальные penumbra wedges рисуются двумя полуклиньями, и для каждого делается либо аддитивный, либо субтрактивный блендинг (деление на два полуклина было необходимо из-за нестыковки между пенумброй и границой чёткой тени, разделение на две части решало проблему). Deferred shaded подход к закраске требует рассчитывать положительное или отрицательное значение coverage (-0.5..0.5), ориентируясь по знаку z компоненты векторного произведения в шейдере.
С этим расчётом таблицы и строились. Но уже в процессе подготовки я понял, что с выборкой в шейдере предрассчитанного значения я тоже сталкиваюсь с проблемой нестыковки на границе чётких теней, из-за ограниченного разрешения субтекстур. Для обхода проблемы я планировал разбить шейдинг пенумбры на два этапа: основную часть закрашивать шейдером с lookup таблицы, а остальные пиксели, близкие к чётким границам - без таблицы. Теперь же мне в голову пришла такая мысль: подготовить таблицу с диапазоном значений [0..0.5], а знак продолжать вычислять в шейдере (две-три инструкции). Т. е. вот есть у нас пиксель на границе чёткой тени. Coverage тут может быть либо 0.5, либо -0.5, как фишка ляжет. Сэмплируем значения, близкие к 0.5 из таблицы, а знак определяем вычислением. Это уберёт большинство проблем, а остальные можно залечить в screen-space.
Пока как-то так. Конечно, окончательные выводы можно будет сделать только после тестов.
Вот как выглядят новые таблицы:


Выглядят они более "правильно", из-за симметрии что-ли. Размер субтекстуры - 32х32, т. е. получается таблица размерностью 1024x1024, при формате R8_UNORM займёт 1 MB видеопамяти (таблицу таких размеров использовали авторы оригинального алгоритма). Возможно, для минимизации проблем с точностью придётся использовать субтекстуру 64x64, а это уже 16 MB видеопамяти.
Подписаться на:
Сообщения (Atom)

