Под него Билл делал свои последние шаги, если кто помнит. Даже если бы и мне довелось умирать, то да - только под этот бриллиант...
понедельник, 26 декабря 2011 г.
Ennio Morricone
Недавно (20 числа) в Киеве был концерт Эннио Морриконе. Сегодня открыл для себя что этот саундтрек написал именно он:
суббота, 24 декабря 2011 г.
Эксимер
Вчера ходил в киевский "Эксимер", делал диагностику зрения.
Капали глаза, мучили несколькими аппаратами.
Зав. отделением сказал что из-за анатомии моего глаза роговица слишком тонкая для LASIK и что годится только LASEK. Период восстановления - до двух недель. К тому же у меня какие-то повреждения в глазу и надо делать укрепление сетчатки лазером перед основной операцией.
Я вычитал что в случае с LASEK после операции два дня болят глаза (из-за повреждения нервных окончаний) и предсказуемость операции ниже, чем при LASIK, так что как-то не хочется её делать. Думаю в следующем году сходить ещё в "Новий Зiр" - пишут у них есть метод Super LASIK Thin Flap, пока единственный в Украине. Думаю стоит попробовать, хотя цены наверное заоблачные. Впрочем, собственные глаза - это явно не тот орган, на котором надо экономить.
Кстати на Ютюбе есть видео с подобной процедурой.
Капали глаза, мучили несколькими аппаратами.
Зав. отделением сказал что из-за анатомии моего глаза роговица слишком тонкая для LASIK и что годится только LASEK. Период восстановления - до двух недель. К тому же у меня какие-то повреждения в глазу и надо делать укрепление сетчатки лазером перед основной операцией.
Я вычитал что в случае с LASEK после операции два дня болят глаза (из-за повреждения нервных окончаний) и предсказуемость операции ниже, чем при LASIK, так что как-то не хочется её делать. Думаю в следующем году сходить ещё в "Новий Зiр" - пишут у них есть метод Super LASIK Thin Flap, пока единственный в Украине. Думаю стоит попробовать, хотя цены наверное заоблачные. Впрочем, собственные глаза - это явно не тот орган, на котором надо экономить.
Кстати на Ютюбе есть видео с подобной процедурой.
DirectGL progress
По работе вытащил уже запылившийся DirectGL, и увидел что многое надо переделать. В итоге меня занесло и я сел дописывать функционал D3DX.
Во-первых, я серьёзно взялся за загрузку текстур через D3DX API. Тут я многое позаимствовал из кодов Wine, а именно иерархию вызовов при загрузке текстуры, различные проверки, способ мэппинга файла в память и т. д. Пока что грузятся палитровые и true-color BMP файлы, TGA с RLE-компрессией и без, работает распознавание DDS файлов. Последний формат довольно сложен (поверхности, cubemap-ы, объёмные текстуры, куча форматов, расширения DX10+), так что надо выкроить время на его поддержку.
Во-вторых, я реализовал загрузку простых файлов формата .x, но быстрым путём: создаются интерфейсы Direct3D для временного окна и грузится реальный меш, потом данные копируются в OpenGL реализацию интерфейса ID3DXMesh :) Конечно этот способ непортируем, зато позволяет проверить насколько работоспособен код рисования.
Результат:

Во-первых, я серьёзно взялся за загрузку текстур через D3DX API. Тут я многое позаимствовал из кодов Wine, а именно иерархию вызовов при загрузке текстуры, различные проверки, способ мэппинга файла в память и т. д. Пока что грузятся палитровые и true-color BMP файлы, TGA с RLE-компрессией и без, работает распознавание DDS файлов. Последний формат довольно сложен (поверхности, cubemap-ы, объёмные текстуры, куча форматов, расширения DX10+), так что надо выкроить время на его поддержку.
Во-вторых, я реализовал загрузку простых файлов формата .x, но быстрым путём: создаются интерфейсы Direct3D для временного окна и грузится реальный меш, потом данные копируются в OpenGL реализацию интерфейса ID3DXMesh :) Конечно этот способ непортируем, зато позволяет проверить насколько работоспособен код рисования.
Результат:

пятница, 23 декабря 2011 г.


четверг, 22 декабря 2011 г.
Radeon 7970
Надеюсь в этот раз Хуанг Энвидиевич не будет бегать по сцене и трясти Кеплером, как он это делал с макетом Ферми.
пятница, 9 декабря 2011 г.
GSC закрылись
Похоже, Сталкера 2 нам уже не дождаться.
Григорович решил закрыть компанию, не объясняя причин.
http://ukranews.com/ru/news/ukraine/2011/12/09/59663
Хватайте новых разработчиков, пока тёпленькие!
Григорович решил закрыть компанию, не объясняя причин.
http://ukranews.com/ru/news/ukraine/2011/12/09/59663
Хватайте новых разработчиков, пока тёпленькие!
понедельник, 5 декабря 2011 г.
Relocation
После двух лет жизни на Оболони я переехал в центр города. Снимаю двухкомнатную квартирку вместе с PANDA (ему одному было дорого). Теперь до офиса - 10 минут неспешным шагом. И да, наконец-то мне больше не придётся спускаться в киевское метро. Ура.
пятница, 18 ноября 2011 г.
OnLive
У нас в офисе появилось вот такое примечательное устройство:
















Качество изображения на 40-дюймовом телевизоре вполне хорошее, артефактов сжатия я не заметил, возможно их видно только на мониторе, или же железо консольки "старается" убрать все огрехи. Чувства, что ты смотришь YouTube в 240p, не возникает. Частота кадров - по мне где-то 20-25, точнее сказать затруднительно. Есть небольшой лаг ввода, но гораздо меньше чем я ожидал, когда начинал играть. Целиться конечно неудобно, консольный геймпад+специфика доставки контента сообща работают против этого. Да и вообще игрок я никудышный :)
В общем, я думаю, что это будущее игровой индустрии. Пройдут годы, Сеть разрастётся оптоволокном, уменьшится пинг и такие вот решения станут вполне жизнеспособны. А если есть хороший интернет, в казуальные и пошаговые игры можно играть уже сейчас. По сути приход on-line моделей доставки контента неизбежен, как неизбежным стало и появление многочисленных торрентов-трекеров в середине 2000-x. Сеть породила массовое пиратство, она же его и убъёт.

Это OnLive(R) Microconsole TV Adapter. Подключается к TV через разъём HDMI, а к геймпаду- через переходник USB/mini-USB.
Кабелёк коротенький, приходится держать консоль на коленях.


У этого экземпляра уже есть аккаунт на серверах OnLive, так что можно играть. Я для пробы поиграл в Splinter Cell: Conviction и Prince Of Persia: The Fogotten Sands.










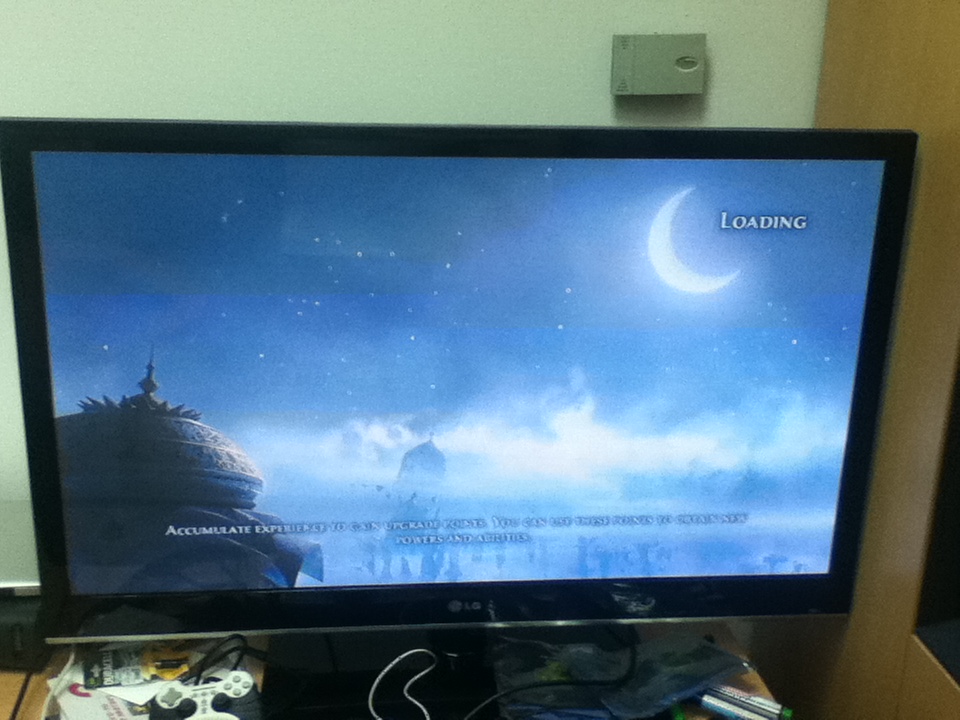


Качество изображения на 40-дюймовом телевизоре вполне хорошее, артефактов сжатия я не заметил, возможно их видно только на мониторе, или же железо консольки "старается" убрать все огрехи. Чувства, что ты смотришь YouTube в 240p, не возникает. Частота кадров - по мне где-то 20-25, точнее сказать затруднительно. Есть небольшой лаг ввода, но гораздо меньше чем я ожидал, когда начинал играть. Целиться конечно неудобно, консольный геймпад+специфика доставки контента сообща работают против этого. Да и вообще игрок я никудышный :)
В общем, я думаю, что это будущее игровой индустрии. Пройдут годы, Сеть разрастётся оптоволокном, уменьшится пинг и такие вот решения станут вполне жизнеспособны. А если есть хороший интернет, в казуальные и пошаговые игры можно играть уже сейчас. По сути приход on-line моделей доставки контента неизбежен, как неизбежным стало и появление многочисленных торрентов-трекеров в середине 2000-x. Сеть породила массовое пиратство, она же его и убъёт.
четверг, 17 ноября 2011 г.
Чикса на Лексусе
Вчера я ехал на работу
в метель, туман и гололёд,
вдруг мимо пронеслась Тойота,
взяла опасный поворот.
Пересекая автостраду
там, где сплошная полоса,
водитель мазалась помадой
и тушью красила глаза!
Как тут от злости не беситься?
Я в гневе бритву уронил
(я дома не успел побриться
и по дороге щёки брил).
Упала бритва в кофе прямо
(между колен стоял стакан -
мне вкусный кофе варит мама -
его я пью в такой туман ).
Когда предмет тяжёлый падал,
крутой горячий кипяток
плеснул туда, куда не надо -
там третьей степени ожог.
И вот от боли я подпрыгнул,
и из моей руки другой
вдруг выпал телефон мобильный -
и снова - в кофе по прямой.
Не помню, что там дальше было...
Открыл глаза: больница? морг?
Теперь ни тачки, ни мобилы...
Зато повязка между ног.
Весь загипсован под завязку,
без гипса только голова.
А вот мораль у этой сказки -
У ВСЕХ БЫ БАБ ЗАБРАТЬ ПРАВА!
пятница, 11 ноября 2011 г.
Китайская грамота
Сегодня нашёл способ заставить шаблонную функцию определять размер массива.
Всё началось с того, что при программировании я использовал несколько вспомагательных шаблонных функций, вроде memzero(), которая является обёрткой над memset() и принимает один параметр вместо трёх:
Всё началось с того, что при программировании я использовал несколько вспомагательных шаблонных функций, вроде memzero(), которая является обёрткой над memset() и принимает один параметр вместо трёх:
template < typename T >Также я завёл один вспомогательный макрос для очистки статических С-arrays:
inline void *memzero(T *p)
{
return memset(p, 0, sizeof(T));
}
#define zeroarray(a) memset(a, 0, sizeof(a));Мне хотелось оформить этот макрос тоже в виде функции, но вся загвоздка в том, что определив параметр как указатель на тип, применить к нему sizeof() нельзя. Первая попытка оформить функцию в виде шаблона выглядила так:
template < typename T, size_t N >Но в данном случае компилятор С++ не может вывести размер массива, и sizeof() выдаёт типичные 4 байта для 32-битной конфигурации. Тепение моё лопнуло и я полез в гугл: после 5 минут гугления выяснилось, что существует такое решение этой проблемы:
inline void zeroarray(T a[N])
{
return memset(a, 0, sizeof(a));
}
template < typename T, size_t N >Я не эксперт в С++, и мне сложно понять, что это за китайская грамота написана в виде параметра функции. Понимаю только одно - выглядит фигово :)
inline void zeroarray(T(&a)[N])
{
return memset(a, 0, sizeof(T) * N);
}
среда, 9 ноября 2011 г.

среда, 2 ноября 2011 г.
Driver Concurrent Creates
Стремление ускорить загрузку программы естественно.
Чем быстрее программа загружается, тем меньше это раздражает пользователя. Применительно к игрострою можно даже помечтать об играх, которые загружаются почти мгновенно :)
С этими мыслями я наблюдаю код некоторых D3D9-движков, содержащих типичную функцию LoadShaders(), которая загружает массив сгенерированных шейдеров (в один поток, разумеется). Время выполнения такой функции может длиться от нескольких секунд и дольше.
В отличие от своих предшественников, Direct3D 11 был спроектирован для поддержки мультипоточности. Вкратце, её поддержка заключается в двух возможностях:
1) Driver Concurrent Creates
2) Driver Command Lists
Первая функциональность позволяет создавать объекты (текстуры, буферы, шейдеры) в разных потоках, а вторая - формировать command buffer в отдельном потоке с дальнейшем "вливанием" его в общий контекст рендеринга. Обе эти функциональности опциональны и зависят от видеодрайвера. Если драйвер их не поддерживает, рантайм будет их эмулировать, но без надежды получить выигрыш в производительности.
В DirectX Caps Viewer в разделе "DXGI 1.1 Devices \ Reference \ Direct3D 11" каждый может посмотреть, поддерживает ли текущий драйвер эти "фичи" (как оказалось, утилита может привирать). Сразу скажу, что Driver Command Lists на момент написания этого поста не реализованы ни у AMD, ни у NVidia. О причинах можно только догадываться. Поддержка Driver Concurrent Creates может варьироваться от системы к системе, но обычно она присутствует.
Создание шейдеров на основе скомпилированного байткода вычислительно ресурсоёмкая задача: рантайм должен распарсить и валидировать байткод, а драйвер - соптимизировать его под конкретную архитектуру и транслировать в машинный код GPU. Использование нескольких ядер CPU в целях ускорения этой задачи оправданно, и если драйвер Direct3D 11 поддерживает эту функциональность, её можно задействовать.
Я решил поиграться с мультипоточной загрузкой шейдеров и написал небольшое тестовое приложение. Исходный код расположен здесь (проект для Visual Studio 2008). Суть его проста: сравнить время загрузки одного и того же количества шейдеров используя один и несколько потоков. Для начала я скрестил Win32 и консольное приложения: нет окна и обработчика оконных сообщений, зато есть консоль с HWND. Для инициализации Direct3D достаточно просто создать устройство, во всём остальном нет надобности. Далее я взял несколько простых шейдеров из состава DirectX SDK, байткод которых заставил грузиться в цикле энное количество раз. Для простоты количество создаваемых потоков равно количеству физических ядер CPU, т. е. по одному на ядро. В конце время выполнения обоих тестов сравнивается и подсчитывается фактор ускорения (он может плавать, что естественно).
С установленными видеокартами (и драйверами) AMD для Core 2 Quad я получил ускорение приблизительно 1.8X, для Core i5 - 2X-2.5X. Что интересно, для NVidia ускорение составляет ~3X, при этом скорость создания шейдеров значительно медленнее, чем в случае с AMD. Не четырёхкратное ускорение, конечно же, но и эти показатели неплохи. Интересно было бы запустить тест на новых 8-ядерных FX-81xx от AMD. Если кому-то выпадет такая возможность - пишите. Также неплохо попробовать использовать в тесте более разнообразные и тяжёлые пиксельные и вычислительные шейдеры.
P.S. Не пытайтесь запускать программу из-под отладчика - в этом случае она ведёт себя некорректно.
Чем быстрее программа загружается, тем меньше это раздражает пользователя. Применительно к игрострою можно даже помечтать об играх, которые загружаются почти мгновенно :)
С этими мыслями я наблюдаю код некоторых D3D9-движков, содержащих типичную функцию LoadShaders(), которая загружает массив сгенерированных шейдеров (в один поток, разумеется). Время выполнения такой функции может длиться от нескольких секунд и дольше.
В отличие от своих предшественников, Direct3D 11 был спроектирован для поддержки мультипоточности. Вкратце, её поддержка заключается в двух возможностях:
1) Driver Concurrent Creates
2) Driver Command Lists
Первая функциональность позволяет создавать объекты (текстуры, буферы, шейдеры) в разных потоках, а вторая - формировать command buffer в отдельном потоке с дальнейшем "вливанием" его в общий контекст рендеринга. Обе эти функциональности опциональны и зависят от видеодрайвера. Если драйвер их не поддерживает, рантайм будет их эмулировать, но без надежды получить выигрыш в производительности.
В DirectX Caps Viewer в разделе "DXGI 1.1 Devices \ Reference \ Direct3D 11" каждый может посмотреть, поддерживает ли текущий драйвер эти "фичи" (как оказалось, утилита может привирать). Сразу скажу, что Driver Command Lists на момент написания этого поста не реализованы ни у AMD, ни у NVidia. О причинах можно только догадываться. Поддержка Driver Concurrent Creates может варьироваться от системы к системе, но обычно она присутствует.
Создание шейдеров на основе скомпилированного байткода вычислительно ресурсоёмкая задача: рантайм должен распарсить и валидировать байткод, а драйвер - соптимизировать его под конкретную архитектуру и транслировать в машинный код GPU. Использование нескольких ядер CPU в целях ускорения этой задачи оправданно, и если драйвер Direct3D 11 поддерживает эту функциональность, её можно задействовать.
Я решил поиграться с мультипоточной загрузкой шейдеров и написал небольшое тестовое приложение. Исходный код расположен здесь (проект для Visual Studio 2008). Суть его проста: сравнить время загрузки одного и того же количества шейдеров используя один и несколько потоков. Для начала я скрестил Win32 и консольное приложения: нет окна и обработчика оконных сообщений, зато есть консоль с HWND. Для инициализации Direct3D достаточно просто создать устройство, во всём остальном нет надобности. Далее я взял несколько простых шейдеров из состава DirectX SDK, байткод которых заставил грузиться в цикле энное количество раз. Для простоты количество создаваемых потоков равно количеству физических ядер CPU, т. е. по одному на ядро. В конце время выполнения обоих тестов сравнивается и подсчитывается фактор ускорения (он может плавать, что естественно).
С установленными видеокартами (и драйверами) AMD для Core 2 Quad я получил ускорение приблизительно 1.8X, для Core i5 - 2X-2.5X. Что интересно, для NVidia ускорение составляет ~3X, при этом скорость создания шейдеров значительно медленнее, чем в случае с AMD. Не четырёхкратное ускорение, конечно же, но и эти показатели неплохи. Интересно было бы запустить тест на новых 8-ядерных FX-81xx от AMD. Если кому-то выпадет такая возможность - пишите. Также неплохо попробовать использовать в тесте более разнообразные и тяжёлые пиксельные и вычислительные шейдеры.
P.S. Не пытайтесь запускать программу из-под отладчика - в этом случае она ведёт себя некорректно.
вторник, 25 октября 2011 г.
суббота, 22 октября 2011 г.

среда, 12 октября 2011 г.
RAGE
Обосрались Вы, товарищ Кармаг, со своим RAGE.
С таким дурацким релизом на PC, когда на половине Radeon-ов игра представляет из себя не пойми какой калейдоскоп или вообще падает, это ещё одно убедительное доказательство, что OpenGL (как стандарт) и его реализация (в драйверах) - унылое говно, и его место возле параши (т. е. на мобильниках).
Конечно, AMD с NVidia наваяют очередные говнопатчи под Вашу конкретную игру, но лучше бы они сделали это заранее, чтобы остальные хомячки не видели этот ебаный стыд. Незнание - это блаженство.
Нет, серьёзно. Пошлите нах..й OpenGL (и OpenCL заодно туда же).
Желаю вам, товарищ Кармаг, разума и осознания.
С таким дурацким релизом на PC, когда на половине Radeon-ов игра представляет из себя не пойми какой калейдоскоп или вообще падает, это ещё одно убедительное доказательство, что OpenGL (как стандарт) и его реализация (в драйверах) - унылое говно, и его место возле параши (т. е. на мобильниках).
Конечно, AMD с NVidia наваяют очередные говнопатчи под Вашу конкретную игру, но лучше бы они сделали это заранее, чтобы остальные хомячки не видели этот ебаный стыд. Незнание - это блаженство.
Нет, серьёзно. Пошлите нах..й OpenGL (и OpenCL заодно туда же).
Желаю вам, товарищ Кармаг, разума и осознания.
среда, 5 октября 2011 г.
понедельник, 26 сентября 2011 г.
суббота, 24 сентября 2011 г.
четверг, 18 августа 2011 г.
Радиус
Сегодня я валялся на пляже в Ялте и смотрел на линию горизонта, где море соединялось с небом. Вдруг подумалось: вот если бы я был сейчас в средних веках (как Колумб), то ведь можно же было бы определить расстояние до линии горизонта - ну например, с помощью мачты на корабле или просто лодки... Так вот, узнав расстояние до горизонта при заданной высоте наблюдения, как тогда вычислить радиус Земли? Ведь эти три величины геометрически связаны самым непосредственным образом, а значит, существует формула, из которой выводится радиус. Но как её записать, я так и не придумал.
понедельник, 8 августа 2011 г.
среда, 3 августа 2011 г.
Дождь
Я вчера в Киеве попал под настоящий ливень - промок до нитки. Кажется, никогда в жизни я так ещё не промокал.
понедельник, 1 августа 2011 г.
пятница, 29 июля 2011 г.
Спалились
Intel спалились - процессор Haswell (наследник Ivy Bridge) получит поддержку DirectX 11.1. Это значит, что Microsoft готовит minor update интерфейса для ОС Windows 8:
И ещё другие любопытные слухи. Говорят, следующие поколения игровых консолей Xbox/Playstation обзаведутся графикой AMD, как раз наверное тогда и DX 11.1 подоспеет. Несложно понять, почему - при равных с NVidia вычислительных возможностях GPU AMD имеют меньшее тепловыделение, что критично для компактных устройств. Я уже начинаю подумывать, а не зря ли NVidia затеяла CUDA на consumer level железе?
вторник, 26 июля 2011 г.
Shaq Retires
Легендарный центровой NBA Шакил О'Нил (Shaquille O'Neal), игравший за такие команды, как LA Lakers и Miami Heat, сообщил о завершении профессиональной карьеры, длившейся 19 лет.
Шак, мы всегда будем помнить тебя как Очень Большого и хорошого парня!
Шак, мы всегда будем помнить тебя как Очень Большого и хорошого парня!
пятница, 22 июля 2011 г.
Multisample soft shadows
В последнее время я размышлял, каким путём следует развивать далее реализацию мягких теней. Ясно, что аппроксимация протяжённого источника света (и. с.) от одной точки неприемлема. Можно ограничиться и. с. небольшой площади: в этом случае ошибки, вызванные аппроксимацией, незначительны. Однако это одно из главных преимуществ алгоритма, и отказываться от него не хочется. Чтобы получить болеё четкое представление об ошибках рендеринга, я дополнил реализацию возможностью работы с несколькими семплами на и. с.: силуэт, теневой объём и пенумбра считаются для каждого семпла. Вот примеры изображений:






1x

4x

1x

4x

Области пенумбры (отладочный рендер)
Хорошо видно, что если аппроксимировать протяжённый источник одним семплом, пенумбра получается неправильная. Несколько семплов вместо одного усложняют и замедляют алгоритм, но становится заметно, например, как разделяются область умбры и пенумбры: тень становится более корректной и правдоподобной. Четыре семпла приводят к бандингу (ну а что вы хотели), тем не менее ясно, что в этом направлении нужно работать дальше.
Авторы оригинальных penumbra wedges не ставили себе задачей вменяемо решить проблему аппроксимации. Если уж и решать её, то точно не увеличением кол-ва семплов (слишком дорого и неуклюже), нужно менять подход. Например, алгоритм изначально опирается на построение теневого объёма из центра и. с., с последующей компенсации пенумбры по краям чёткой тени. Я думаю, что правильным будет пойти таким путём: считаем coverage в пенумбре без знака (он зависит от того, находимся мы в тени или вне её), а вместо стандартной чёткой тени для центра и. с. определяем область умбры и закрашиваем её чёрным - вклад в освещённость там полностью отсутствует. Получается две логичные части: умбра, где нет освещённости, и пенумбра, где пиксельный шейдер аналитически её высчитывает. Непонятно, как рассчитать умбру для протяжённого источника: приближения тут опасны, если произойдёт "нестыковка" между умброй и пенумброй, в изображении появятся артефакты. В принципе, если мы рассчитываем области пенумбры, то определённо можно выделить и область умбры, но сказать это, увы, проще, чем написать стабильную реализацию.
Я планирую пока вернуться к шлифовке и оптимизации пиксельных шейдеров, например, хочется наконец-то попробовать четырёхмерные таблицы с предрассчитанной освещённостью, вместо того, чтобы считать её в шейдере аналитически - это поможет уменьшить его длину и теоретически ускорить шейдинг. А также отрефакторить код рендера, отшлифовать детали и т. д. Но уже ясно, что геометрическую часть алгоритма нужно менять, как именно - покажет время.
четверг, 14 июля 2011 г.
суббота, 9 июля 2011 г.
понедельник, 4 июля 2011 г.
GL_EXTENSIONS
Попытался сегодня поиграть в Quake II (не смейтесь - игра всех времён) на своём ноуте и не смог - игра падала. Режим совместимости никаких результатов не дал.
Разыскал на диске q2source-3.21, собрал отладочный билд, переназначил пути - запускаю. Падает. Начал разбираться - дошёл до инициализации ref_gl и увидел, что движок спотыкается о стандартную ошибку - buffer overflow при попытке вывести строчку GL_EXTENSIONS. Дело в том, что константа MAXPRINTMSG (функция VID_Printf) равна 4096, чего недостаточно для такой строки в наше время - слишком уж она разрослась за все эти годы. Если константу увеличить вдвое - проблема уходит. С - небезопасный язык :)
Эта проблема была решена в OpenGL 3.x, где вы получаете не весь список расширений сразу в одной строке, а имя каждого отдельного расширения по индексу. Надо было сделать так изначально при дизайне API, но никто ведь тогда не думал, что механизм расширений превратится в такой дурдом, а?
Разыскал на диске q2source-3.21, собрал отладочный билд, переназначил пути - запускаю. Падает. Начал разбираться - дошёл до инициализации ref_gl и увидел, что движок спотыкается о стандартную ошибку - buffer overflow при попытке вывести строчку GL_EXTENSIONS. Дело в том, что константа MAXPRINTMSG (функция VID_Printf) равна 4096, чего недостаточно для такой строки в наше время - слишком уж она разрослась за все эти годы. Если константу увеличить вдвое - проблема уходит. С - небезопасный язык :)
Эта проблема была решена в OpenGL 3.x, где вы получаете не весь список расширений сразу в одной строке, а имя каждого отдельного расширения по индексу. Надо было сделать так изначально при дизайне API, но никто ведь тогда не думал, что механизм расширений превратится в такой дурдом, а?
среда, 29 июня 2011 г.
Samsung SA750
Корейская компания Samsung запускает LED-мониторы нового поколения, с поддержкой 3D (т. е. стерео посредством 120 Гц). Я, например, хочу такой:

Одно важное изменение, которое не сразу бросается глаза - начиная с этого поколения, Samsung решили наконец-то избавиться от старого порта DVI в пользу HDMI 1.4 и DisplayPort, разорвав таким образом порочный круг. Правда прямо сейчас в этом есть и свой минус - надо апгрейдиться до видео с поддержкой DisplayPort (AMD), или искать переходник DVI->DP (NVidia).

:)
Update
Уже появились на российских складах:
http://itrate.ru/cgi-bin/show.pl?option=full_retail_news&id=8269
Обзор соседней линейки на xbitlabs:
Samsung SyncMaster SA950 Monitor: 3D Beauty

Одно важное изменение, которое не сразу бросается глаза - начиная с этого поколения, Samsung решили наконец-то избавиться от старого порта DVI в пользу HDMI 1.4 и DisplayPort, разорвав таким образом порочный круг. Правда прямо сейчас в этом есть и свой минус - надо апгрейдиться до видео с поддержкой DisplayPort (AMD), или искать переходник DVI->DP (NVidia).

:)
Update
Уже появились на российских складах:
http://itrate.ru/cgi-bin/show.pl?option=full_retail_news&id=8269
Обзор соседней линейки на xbitlabs:
Samsung SyncMaster SA950 Monitor: 3D Beauty
среда, 15 июня 2011 г.
понедельник, 13 июня 2011 г.
Я в Бухаресте
Начальство предложило приехать в Ubisoft Bucharest для решения местных проблем. Беготня с паспортом и визой, полтора часа полёта - и вот я здесь. Пробыть предполагается два месяца.

P.S. Здесь нет русской клавиатуры, клацаю по нужным клавишам с помощью моторной памяти :)

P.S. Здесь нет русской клавиатуры, клацаю по нужным клавишам с помощью моторной памяти :)
пятница, 3 июня 2011 г.
Rectangular light source
На днях сидел по вечерам за отладкой шейдера пенумбры для прямоугольного источника света. Все мои предыдущие реализации мягких теней использовали только сферический источник света, с прямоугольным как-то не ладилось. В конце-концов я написал алгоритм шейдера на C++ и отладил несколько тестовых случаев. Оказалось, что корректное решение требует инвертирования матрицы 3x3 прямо в пиксельном шейдере, чего в оригинальной реализации алгоритма я не увидел. Программная реализация помогла обсосать все тонкости алгоритма (что с HLSL и GPU-ориентированными инструментами, я считаю, сделать невозможно или крайне затруднительно).



Из-за лоу-поли геометрии и прямоугольности источника света пенумбра выглядит угловатой. Но главная проблема носит название single point silhouette approximation, о ней я уже писал здесь. Из-за этого упрощения тени выглядят как overshadowed, потому что не все потенциальные силуэтные рёбра внесли свой вклад в пенубмру. То, как выглядят тени сейчас, меня не устраивает, поэтому так или иначе придётся реализовывать корректный поиск силуэта.



Из-за лоу-поли геометрии и прямоугольности источника света пенумбра выглядит угловатой. Но главная проблема носит название single point silhouette approximation, о ней я уже писал здесь. Из-за этого упрощения тени выглядят как overshadowed, потому что не все потенциальные силуэтные рёбра внесли свой вклад в пенубмру. То, как выглядят тени сейчас, меня не устраивает, поэтому так или иначе придётся реализовывать корректный поиск силуэта.
вторник, 31 мая 2011 г.

Маурицио
Никто не знал, где он ночует и что он ест. О нем говорили, будто он колдун, потому что он умел играть на всех инструментах и играл блестяще, а жил всегда бесприютным, нищим бродягой. Вот этот Маурицио послушал, как звучит виола да гамба моего деда, и предложил ему обмен: дед отдаст ему инструмент, а Маурицио откроет ему тайну жизни. Дед согласился - каждый человек в семнадцать лет хочет заранее узнать тайну бытия. И тогда Маурицио сказал деду, что тот должен сделать еще триста девяносто девять инструментов - на четырехсотой скрипке его ждет бессмертие.
С тех пор в деда Андреа будто вселился демон. Он работал как галерник, дни и ночи, случалось, что по трое суток он не выходил из мастерской, руки его были изъедены кислотами и растворителями, в мозолях, порезах и ссадинах, с трех пальцев были сорваны ногти, и больше они не выросли.
Он сделал около пятисот инструментов, и когда перед смертью от него ушел исповедник, я спросил деда, а было мне тогда девять лет:
- Этот противный сумасшедший колдун Маурицио обманул вас, синьор?
Дед был совсем старый, просто усохший от времени, весь
пергаментно-желтый, только глаза и руки жили еще в нем. Он засмеялся и сказал мне:
- Никколо, мой мальчик, когда ты вырастешь, ты поймешь, что Маурицио не колдун и не сумасшедший. Он добрый и мудрый музыкант. Когда мне было семнадцать лет, он никак не смог бы заставить меня работать так всю жизнь, как я работал, посулив мне за это меньше, чем бессмертие. Маурицио знал, в чем истинное бессмертие человеческое, и я умираю с благодарностью ему и надеждой, что он выполнил хоть частично свое обещание...
С тех пор в деда Андреа будто вселился демон. Он работал как галерник, дни и ночи, случалось, что по трое суток он не выходил из мастерской, руки его были изъедены кислотами и растворителями, в мозолях, порезах и ссадинах, с трех пальцев были сорваны ногти, и больше они не выросли.
Он сделал около пятисот инструментов, и когда перед смертью от него ушел исповедник, я спросил деда, а было мне тогда девять лет:
- Этот противный сумасшедший колдун Маурицио обманул вас, синьор?
Дед был совсем старый, просто усохший от времени, весь
пергаментно-желтый, только глаза и руки жили еще в нем. Он засмеялся и сказал мне:
- Никколо, мой мальчик, когда ты вырастешь, ты поймешь, что Маурицио не колдун и не сумасшедший. Он добрый и мудрый музыкант. Когда мне было семнадцать лет, он никак не смог бы заставить меня работать так всю жизнь, как я работал, посулив мне за это меньше, чем бессмертие. Маурицио знал, в чем истинное бессмертие человеческое, и я умираю с благодарностью ему и надеждой, что он выполнил хоть частично свое обещание...
пятница, 27 мая 2011 г.
День рождения
У блога сегодня день рождения - ему исполнилось два года :)
По этому поводу я приготовил (сидел допоздна) несколько скриншотов:




Код не отполирован, множество визуальных артефактов, ещё есть множество вещей, которые я хочу реализовать и отладить. Но впервые за всё время мягкие тени делаются с поддержкой Direct3D 11.
И ещё одно. Начиная с этого дня я решил завести англоязычную версию блога, в котором я буду публиковать переводы своих ключевых постов (и совершенствовать свой английский): joescg-en.blogspot.com.
По этому поводу я приготовил (сидел допоздна) несколько скриншотов:




Код не отполирован, множество визуальных артефактов, ещё есть множество вещей, которые я хочу реализовать и отладить. Но впервые за всё время мягкие тени делаются с поддержкой Direct3D 11.
И ещё одно. Начиная с этого дня я решил завести англоязычную версию блога, в котором я буду публиковать переводы своих ключевых постов (и совершенствовать свой английский): joescg-en.blogspot.com.
вторник, 24 мая 2011 г.
суббота, 21 мая 2011 г.
3DMark 11
Прочитал я обзор и анализ уже давно вышедшего 3DMark 11, закручинился.
Печально всё обстоит в нашем королевстве, при том что GPU сильны и умны, как никогда прежде. Похоже, CG отныне будет развиваться только скачками, от старого поколения консолей к новым, с периодом этак лет в... 10.
Печально всё обстоит в нашем королевстве, при том что GPU сильны и умны, как никогда прежде. Похоже, CG отныне будет развиваться только скачками, от старого поколения консолей к новым, с периодом этак лет в... 10.
среда, 18 мая 2011 г.
Packed Stream Output
Есть такой перекос в D3D 10/11 железе - input layout может фетчить данные из вершинного буфера в разнообразных форматах, а вот stream output может выводить только 32-битные значения (написано в са-а-амом конце раздела Getting Started with the Stream-Output Stage). Между тем, обычно float точность сильно избыточна для небольших моделей, и хотелось бы иметь возможность выводить данные типа half.
SM 5.0 предоставляет две функции для конвертирования float в half и обратно: f32tof16() и f16tof32(). Для них есть dedicated silicon в D3D11-железе и подразумевается, что они first-class citizen. Также эти функции могут применяться в SM 4.0, в этом случае они эмулируются программно - в шейдер вставляются многочисленные операции битового сдвига, целочисленного сложения и т. д. Я случайно нашёл С-аналоги этих функциий в OpenGL RedBook: Floating-Point Formats Used in OpenGL (вероятнее всего, алгоритм следует стандарту IEEE 754-2008 для half precision floating-point format). В своё время я написал подобные функции конвертирования, работающие в шейдере посредством lookup table, но в свете SM 5.0 это уже устарело :)
У меня появилась идея, что с помощью этих функций можно в геометрическом шейдере паковать два float-значения в один, ужимая каждый в half, и т. о. снизить нагрузку на stream output и на input assembler. Кроме того, можно уменьшить важный параметр maxvertexcount геометрического шейдера: например, если ранее GS выводил две вершины, то теперь достаточно одной. Общая идея такова: SO выводит по два half, запакованных во float, а IA интерпретирует вершинный буфер как R16G16B16A16_FLOAT, т. о. мы сможем легко читать каждую запакованную вершину.
Вот код упаковки двух трёхкомпонентных векторов в один четырёхкомпонентный: pck. Четвёртый компонент необходим вследствие того, что формат R16G16B16A16_FLOAT имеет четыре компоненты (6-байтные форматы с тремя компонентами не поддерживаются), но его можно игнорировать при чтении из вершинного буфера, а значит, и при упаковке.
Всё легко пакуется до тех пор, пока вы выводите чётное кол-во вершин: 2, 4 и т. д. А если нужно вывести 3 вершины (треугольник)? Можно запаковать первые две в один vec4, третью - в компоненты .xy второго vec4, компоненты .zw - оставить пустыми. Но при последующем чтении треугольника мы прочитам три half4, а пустой четвёртый будет относиться уже к следующему примитиву - ошибка! Указать же stride между примитивами в вершинном буфере невозможно - никому в голову не придёт идея оставлять в памяти ненужные "дырки".
Решение простое. Если раньше мы сжимали, скажем, четыре вершины в две, то теперь надо сжать три в одну:
В IA читаем данные из вершинного буфера как поледовательность half4 - и всё.
SM 5.0 предоставляет две функции для конвертирования float в half и обратно: f32tof16() и f16tof32(). Для них есть dedicated silicon в D3D11-железе и подразумевается, что они first-class citizen. Также эти функции могут применяться в SM 4.0, в этом случае они эмулируются программно - в шейдер вставляются многочисленные операции битового сдвига, целочисленного сложения и т. д. Я случайно нашёл С-аналоги этих функциий в OpenGL RedBook: Floating-Point Formats Used in OpenGL (вероятнее всего, алгоритм следует стандарту IEEE 754-2008 для half precision floating-point format). В своё время я написал подобные функции конвертирования, работающие в шейдере посредством lookup table, но в свете SM 5.0 это уже устарело :)
У меня появилась идея, что с помощью этих функций можно в геометрическом шейдере паковать два float-значения в один, ужимая каждый в half, и т. о. снизить нагрузку на stream output и на input assembler. Кроме того, можно уменьшить важный параметр maxvertexcount геометрического шейдера: например, если ранее GS выводил две вершины, то теперь достаточно одной. Общая идея такова: SO выводит по два half, запакованных во float, а IA интерпретирует вершинный буфер как R16G16B16A16_FLOAT, т. о. мы сможем легко читать каждую запакованную вершину.
Вот код упаковки двух трёхкомпонентных векторов в один четырёхкомпонентный: pck. Четвёртый компонент необходим вследствие того, что формат R16G16B16A16_FLOAT имеет четыре компоненты (6-байтные форматы с тремя компонентами не поддерживаются), но его можно игнорировать при чтении из вершинного буфера, а значит, и при упаковке.
Всё легко пакуется до тех пор, пока вы выводите чётное кол-во вершин: 2, 4 и т. д. А если нужно вывести 3 вершины (треугольник)? Можно запаковать первые две в один vec4, третью - в компоненты .xy второго vec4, компоненты .zw - оставить пустыми. Но при последующем чтении треугольника мы прочитам три half4, а пустой четвёртый будет относиться уже к следующему примитиву - ошибка! Указать же stride между примитивами в вершинном буфере невозможно - никому в голову не придёт идея оставлять в памяти ненужные "дырки".
Решение простое. Если раньше мы сжимали, скажем, четыре вершины в две, то теперь надо сжать три в одну:
struct gs_out
{
vec4 pos1_pos2 : Data0;
vec2 pos3 : Data1;
};
[maxvertexcount(1)]
void gs_main(..., inout PointStream< gs_out > stream)
{
...
}
В IA читаем данные из вершинного буфера как поледовательность half4 - и всё.
понедельник, 9 мая 2011 г.
Дом
Вам знакомо это ощущение - когда лучшие фильмы с торрентов уже много раз пересмотрены, и вы без особой надежды пытаетесь выловить что-нибудь новое или, что лучше, хорошо забытое старое. Вот в таком настроении я как-то случайно наткнулся на фильм "Дом из песка и тумана".
Помню, как начал смотреть его без особого энтузизма, но спустя некоторое время вдруг понял, что с этим фильмом не всё так просто. Скажу сразу - досмотреть его до конца оказалось очень тяжело (иногда хотелось всё остановить), и остаток дня я сильно переживал увиденное. Неожиданно фильм оказался тяжелейшей драмой, если только в этой категории уместно выдавать первые "места". Это не бездарное артхаусное кино, под которое хорошо засыпать на ночь, но удивительное творение гениального режиссёра (нашего соотечественника, к слову).
С тех пор я больше не пересматривал его - мне хватило одного раза. А вот сегодня случайно узнал, что прокат фильма в США даже не отбил его скромный бюджет. Это не удивительно, ведь под него не почавкаешь попкорном, а желание просто поржать быстро пропадает. И всё же мне стало немного грустно, что снимать такие фильмы - это рисковать своими положением и финансами, и я просто решил написать об этом фильме - пускай хотя бы ещё несколько человек узнает о нём.
Помню, как начал смотреть его без особого энтузизма, но спустя некоторое время вдруг понял, что с этим фильмом не всё так просто. Скажу сразу - досмотреть его до конца оказалось очень тяжело (иногда хотелось всё остановить), и остаток дня я сильно переживал увиденное. Неожиданно фильм оказался тяжелейшей драмой, если только в этой категории уместно выдавать первые "места". Это не бездарное артхаусное кино, под которое хорошо засыпать на ночь, но удивительное творение гениального режиссёра (нашего соотечественника, к слову).
С тех пор я больше не пересматривал его - мне хватило одного раза. А вот сегодня случайно узнал, что прокат фильма в США даже не отбил его скромный бюджет. Это не удивительно, ведь под него не почавкаешь попкорном, а желание просто поржать быстро пропадает. И всё же мне стало немного грустно, что снимать такие фильмы - это рисковать своими положением и финансами, и я просто решил написать об этом фильме - пускай хотя бы ещё несколько человек узнает о нём.
пятница, 6 мая 2011 г.
T-junction elimination
При рендеринге теней от md2 мешей появились артефакты. Как выяснилось, даже лоу-поли модели из Quake II не лишены багов (а я надеялся, что всё будет отлично). Видимо, это из-за того, что изначально они не предназначались для отбрасывания теней, хотя заметно, что при их моделировании соблюдались правила замкнутости.
В общем, конвертер пришлось дорабатывать, чтобы он мог выделять кластеры несмежных треугольников, обходить T-junction, делать поиск по совпадающим координатам и т. д. В итоге мне удалось обойти в моделях мелкие ошибки и убрать из adjacency невалидные треугольники.



В принципе, целый ряд моделей не содержит никаких ошибок. А вот например, у bitch выпало целое плечо (как оказалось, там какая-то каша из треугольников).
В общем, конвертер пришлось дорабатывать, чтобы он мог выделять кластеры несмежных треугольников, обходить T-junction, делать поиск по совпадающим координатам и т. д. В итоге мне удалось обойти в моделях мелкие ошибки и убрать из adjacency невалидные треугольники.



В принципе, целый ряд моделей не содержит никаких ошибок. А вот например, у bitch выпало целое плечо (как оказалось, там какая-то каша из треугольников).
пятница, 29 апреля 2011 г.
Плакат SC:C
К нам в офис привезли замечательный плакат "по мотивам" нашего проекта:


Есть ещё парочка других, но это уже не так интересно.
вторник, 26 апреля 2011 г.
Depth of Field: First Experiments
Начал экспериментировать с различными реализациями depth of field. Тема эта очень сложная, поэтому для начала решил попробовать несколько brute-force методов для получения референсного изображения, отталкиваясь от которого, можно было бы подгонять real-time технику до нужного качества.
Первый вариант, он же самый простой: рендеринг из различных положений на виртуальной линзе в буфер с накоплением:


Используется 48 сэмплов, для каждого кадра инстансингом рисуется 1024 кубика, расстояние до фокальной плоскости учитывается при построении look-at матрицы. 48 "выборок" явно недостаточно для сглаженного изображения, очень виден бандинг. Нужно как минимум 128, и хорошо посчитанный kernel. Можно получить очень хороший depth of field, качеством напоминающий ray-tracing.
Второй вариант: для каждого пикселя экрана рисуется вершина, которую геометрический шейдер раздувает в спрайт нужного диаметра, который аддивно смешивается с содержимым в буфере кадра. Чудовищный способ, но по идее должен был дать хороший эффект для данной сцены. Пока не получается сохранять исходную энергию изображения, есть артефакты и т. д.

Немного о реализации: с помощью инстансинга рисуются всё те же 1024 кубика, в depth буфер выводится view space z. Затем рисуется w * h вершин, по одной вершине в каждом пикселе окна. Чтобы снизить нагрузку, вершинный буфер не используется, вызовы вершинного шейдера генерируются вызовом DrawInstanced(), в шейдере используется семантика SV_InstanceID для расчёта экранных координат. Вершинный шейдер сэмплирует цвет и глубину и передаёт данные в геометрический шейдер. Последний рассчитывает диаметр circle of confusion и раздувает вершину в спрайт нужного размера. Ну а дальше блендинг в PS. Техника упирается, как ни странно, не в геометрический pipeline, а в блендинг в FP-render target.
Следующий шаг - разбор уравнений, по которым рассчитывается правильный CoC (как оказалось, у всех - по-разному).
Update
Сегодня построил график изменения радиуса circle of confusion в зависимости от параметров оптической системы: диаметра линзы, фокального расстояния и фокальной плоскости. Для построения была взята формула из пейпра Dynamic Light Field Generation and Filtering:

По характеру кривой график совпал с тем, что приведён в другом пейпре по DoF: Pyramidal Image Processing. Естественно, что на кривую влияют выбранные параметры и характер масштабирования по оси Y, т. к. размеры CoC меняются далеко нелинейно. Но вот например в слайдах Advanced Real-Time Depth of Field Techniques приводится другой график:

и не совсем ясно, по какой формуле он считался. Будем думать :)
Первый вариант, он же самый простой: рендеринг из различных положений на виртуальной линзе в буфер с накоплением:


Используется 48 сэмплов, для каждого кадра инстансингом рисуется 1024 кубика, расстояние до фокальной плоскости учитывается при построении look-at матрицы. 48 "выборок" явно недостаточно для сглаженного изображения, очень виден бандинг. Нужно как минимум 128, и хорошо посчитанный kernel. Можно получить очень хороший depth of field, качеством напоминающий ray-tracing.
Второй вариант: для каждого пикселя экрана рисуется вершина, которую геометрический шейдер раздувает в спрайт нужного диаметра, который аддивно смешивается с содержимым в буфере кадра. Чудовищный способ, но по идее должен был дать хороший эффект для данной сцены. Пока не получается сохранять исходную энергию изображения, есть артефакты и т. д.

Немного о реализации: с помощью инстансинга рисуются всё те же 1024 кубика, в depth буфер выводится view space z. Затем рисуется w * h вершин, по одной вершине в каждом пикселе окна. Чтобы снизить нагрузку, вершинный буфер не используется, вызовы вершинного шейдера генерируются вызовом DrawInstanced(), в шейдере используется семантика SV_InstanceID для расчёта экранных координат. Вершинный шейдер сэмплирует цвет и глубину и передаёт данные в геометрический шейдер. Последний рассчитывает диаметр circle of confusion и раздувает вершину в спрайт нужного размера. Ну а дальше блендинг в PS. Техника упирается, как ни странно, не в геометрический pipeline, а в блендинг в FP-render target.
Следующий шаг - разбор уравнений, по которым рассчитывается правильный CoC (как оказалось, у всех - по-разному).
Update
Сегодня построил график изменения радиуса circle of confusion в зависимости от параметров оптической системы: диаметра линзы, фокального расстояния и фокальной плоскости. Для построения была взята формула из пейпра Dynamic Light Field Generation and Filtering:

По характеру кривой график совпал с тем, что приведён в другом пейпре по DoF: Pyramidal Image Processing. Естественно, что на кривую влияют выбранные параметры и характер масштабирования по оси Y, т. к. размеры CoC меняются далеко нелинейно. Но вот например в слайдах Advanced Real-Time Depth of Field Techniques приводится другой график:

и не совсем ясно, по какой формуле он считался. Будем думать :)
вторник, 19 апреля 2011 г.
MacOS X 10.7 Preview
По слухам, Apple наконец-то добавляет поддержку OpenGL 3.2 в новой версии операционной системы:
Apple releases first developer preview of MacOS X Lion
И да, наконец-то размер окна можно изменять, хватаясь мышкой за любую его рамку!
Apple releases first developer preview of MacOS X Lion
И да, наконец-то размер окна можно изменять, хватаясь мышкой за любую его рамку!
пятница, 15 апреля 2011 г.
Бомбы не оказалось
Я обычно возвращаюсь домой через станцию метро "Университет". Но вчера распорядок дня выбился из привычной колеи: станцию оцепили, милиция преграждала проход. Я заснял это безобразие на камеру iPod-а:


В новостях написали, что якобы была обнаружена бомба. Позже выяснилось, что никакой бомбы нет. Вместо неё был сломанный мобильник в помятом пакете из "Макдональдса".


В новостях написали, что якобы была обнаружена бомба. Позже выяснилось, что никакой бомбы нет. Вместо неё был сломанный мобильник в помятом пакете из "Макдональдса".
четверг, 7 апреля 2011 г.
D3D10 MRT
Output-Merger Stage (Direct3D 10), почти в самом конце подраздел Multiple RenderTargets Overview:
... Furthermore, all render targets must have the same size in all dimensions (width, height, depth, array size, sample counts). Each render target may have a different data format.
Как-то до сих пор ускользало от меня. И да, в Direct3D 9 depth буфер по размерам может быть больше, чем render target.
... Furthermore, all render targets must have the same size in all dimensions (width, height, depth, array size, sample counts). Each render target may have a different data format.
Как-то до сих пор ускользало от меня. И да, в Direct3D 9 depth буфер по размерам может быть больше, чем render target.
вторник, 5 апреля 2011 г.

понедельник, 28 марта 2011 г.
Splinter Cell: Conviction
На http://www.macgamestore.com/ появился порт Splinter Cell: Conviction (Капитан Очевидность подсказывает, что это для Mac). Игра доступна посредством цифровой дистрибуции по цене $19.99:










Это проект, над портированием графической составляющей которого я и работал в Ubisoft Kiev весь последний год. Да, юбики решили портировать свои крупнейшие AAA-тайтлы на Mac, и это при том что SCC вначале вообще объявлялся как Microsoft-exclusive проект!
Изначально планировалось зарелизить проект 29 октября 2010, до старта рождественских продаж, но сроки мы благополучно зафейлили и начальству пришлось даты сдвигать. Мы всё же успешно довели проект до рабочего состояния, и через некоторое время он должен появиться и в Mac App Store (уже без DRM - требование яблочников).
Удачного плавания, Сэм!


Подписаться на:
Комментарии (Atom)

